Some programming languages provide first-class support for documentation. Rust is well known for automatically generating high quality docs which can be accessed locally with rustdoc and at docs.rs. The Rust auto-generated docs are unusual in how readable they are, unlike many other automated API docs.
This solves a common problem whereby examples drift as code changes. If the examples are executed as tests then incorrect examples will fail the build. This helps enforce the idea that development isn’t “finished” until it’s fully documented and tested.
Elixir does something similar with doctests. Go also compiles (and optionally executes) the code in examples and builds docs automatically. The Go packages site has become a popular go-to resource as a result.
This is a shame because I commonly come across example code in docs that just doesn’t work. This is really annoying for a) the user trying to figure out how to use something; b) the developer trying to keep on top of everything.
Top-quality, detailed documentation is something we aim for at Arcjet. Our security SDK allows developers to quickly build things like rate limiting and email verification - critical components that are easy to get going, but have a lot of options for power users to extend. Our first SDK is for JS (Next.js and Node.js) so we’ve been writing a lot of sample code.
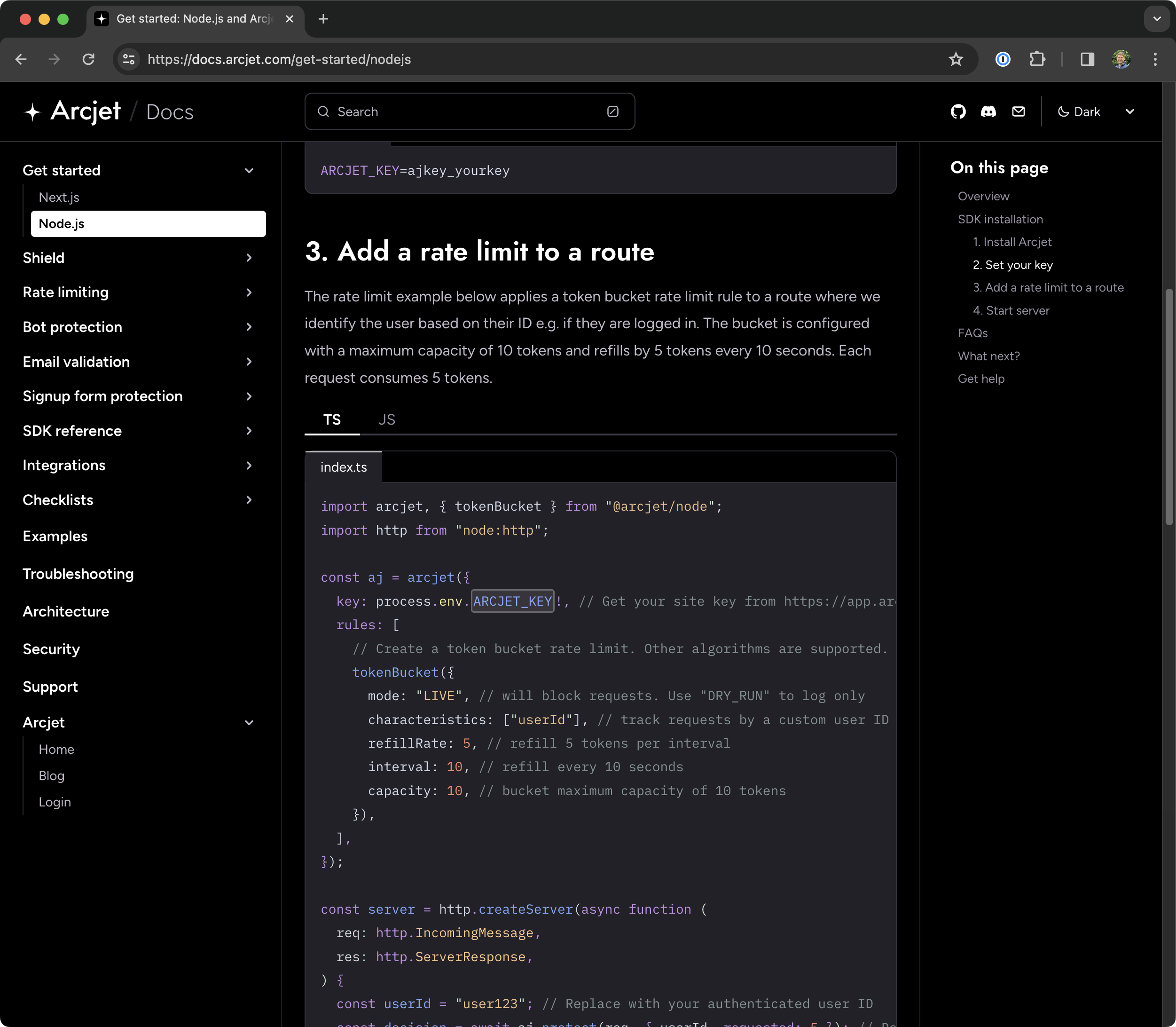
Arcjet docs using Starlight and showing a code sample loaded in from a file.
Write code samples as individual files
There’s code documentation - which is written as comments in the source code - and then there’s product documentation - most commonly written in Markdown and/or in a SaaS product like Readme or Mintlify. You often need both. In-code is useful for libraries to be picked up by IDEs and used as reference docs whereas product docs are for quick starts, more detailed explanations, samples, tutorials, etc.
The most common pattern I’ve seen is writing code samples in Markdown as triple backtick fenced code blocks. This gives you nice syntax highlighting, but doesn’t verify the code is accurate. Writing code inside Markdown prevents you from relying on the language tooling to help you out.
The way to solve this is to write your code samples as separate files and then have them loaded by the docs framework at build time. This allows you to write actual code with all the normal tooling provided by your editor, linter, compiler, etc. You can also write tests and build the code as part of your CI/CD process.
Loading code samples from files
Our original prototype documentation used the Nextra documentation framework powered by Next.js. This has Shiki built-in for syntax highlighting which is a really powerful highlighting framework, but doesn’t support loading code samples from disk.
We swapped out Shiki for CodeHike which has a from annotation (docs) that allows you to reference a file in the code block. It even supports loading just a portion of the file so you can strip out boilerplate. This allowed us to write the code snippets as normal files and load them into the Markdown code block.
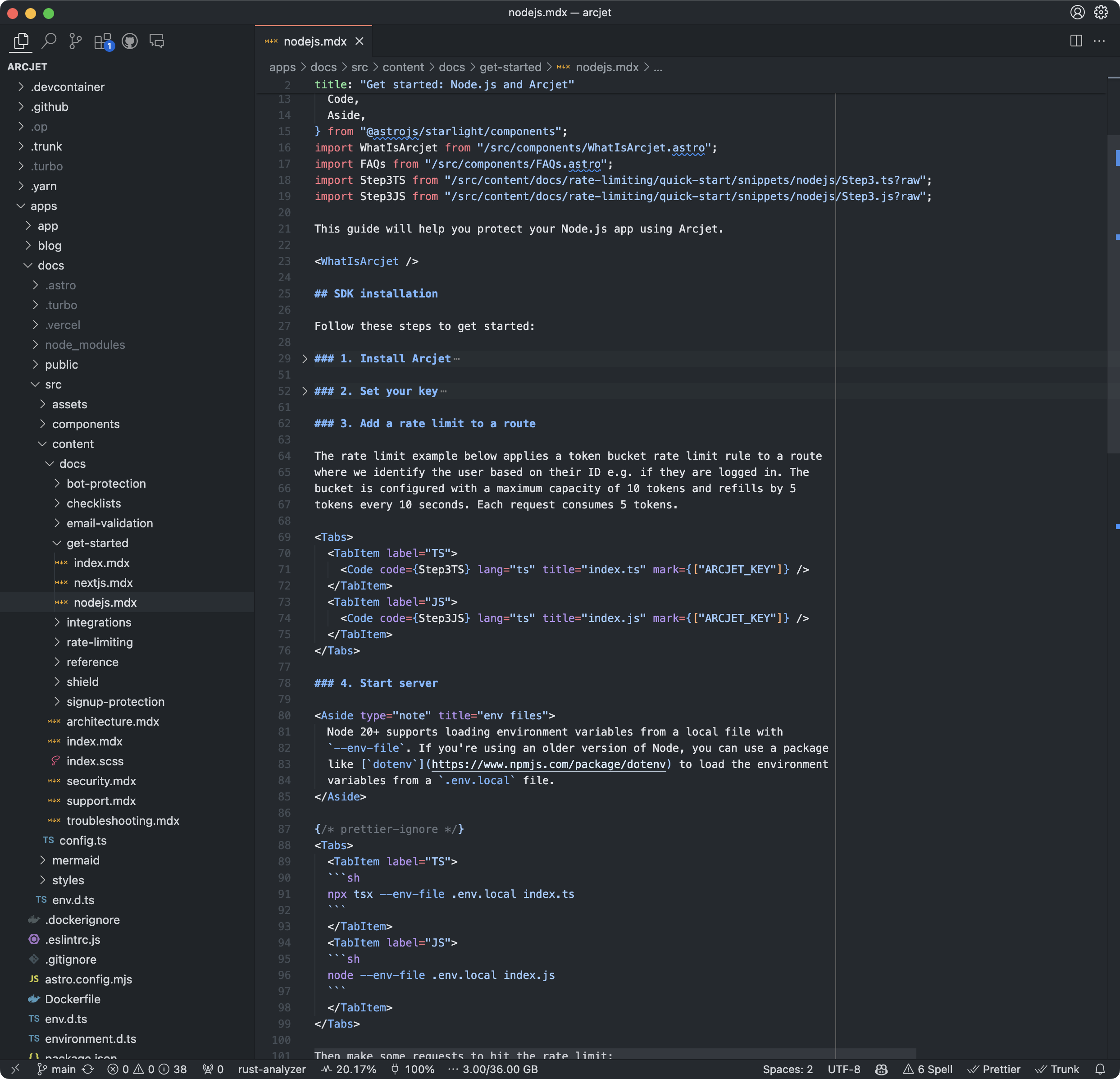
As our docs became more complex, we switched to Starlight which is based on the Astro framework. The 0.17.0 Starlight release added a new <Code> component (docs) which supports loading a raw source file into the component which will then be processed for highlighting. It uses Expressive Code which gives you powerful configuration options like diff views, text markers, collapsable sections and line numbers. We’ve come full circle because it’s using Shiki for highlighting!
Screenshot of the Arcjet docs source with some in-line code and some code loaded from files.
More than just code samples
This is just one aspect of the effort we’re trying to put into keeping our docs accurate. By loading samples from files we know when the code fails to parse or build, but we still don’t know whether it actually works without manually testing.
Other things we’re considering how to automate include testing whether updates cause breaking changes, versioning the SDK and maintaining old docs, and ensuring links all work (we now use a link validator Starlight plugin for this). Figuring out how to make this all work with other languages like Python and Ruby will be another challenge.
These are all areas for improvement on our roadmap!
The Arcjet Python SDK allows you to implement rate limiting, bot detection, email validation, and signup spam prevention in FastAPI and Flask style applications.