Arcjet makes it easy to remove entire classes of security problems from your applications, such as denying misbehaving bots from your websites. Today we're going to cover the inherent complexity in bot detection and how your app is protected from bots by Arcjet.
Security is a complicated topic and anyone that claims to perfectly solve it is probably trying to sell you something. The only way to really make sure that a system is fully protected from the outside world is to take that system, unplug it from the internet, and bury it deep in a ditch surrounded by 50 tons of water in all directions. This really isn't ideal if your goal is to sell widgets to people on the internet. Kinda hard for the packets to get into a system, computing to run, or the storage to work in such an environment.
One of the biggest security compromises you end up having to make on a regular basis is when to allow or deny traffic to your application. Generally, allowing paying customers to access your application allows them to pay you money, which is great if your goal is to make money. Money makes the investors happy and allows you to acquire nice things such as food, rent, and cloud compute time.
Unfortunately, not every user on the Internet is a paying customer. For any given set of requests, about 10% of them are requests from actual humans, and even then the acquisition funnel logic means that you can get as few as 1% of those actual human requests converting into paying customers. The other 90% of requests you get are from bots. Well-behaved bots like Google's crawler are very much wanted (ranking highly on Google typically is connected to success in your business), but there's a deep underbelly of bots that will click on every link on your website as fast as possible and as much as possible so they can gobble up everything you've ever published for questionable uses in giant piles of linear algebra that no human can hope to fully understand.
Helpfully, the HTTP specification (RFC2616) allows clients to declare the "user agent" of a request. This means that you can easily detect bots by their User-Agent header and deny requests as appropriate.
Unfortunately, humans have invented a social construct known as "lying", which makes this a lot more complicated. Through lying, cars are able to fly, birds are declared by the government as real living animals, and crawler bots can disguise themselves as normal web browsers.
The spherical cow internet bot
🗒️
Any time you see Pascal-Kebab-Case-Words, assume that I'm talking about the HTTP header by that name.
For a moment, let's pretend that all that nonsense about lying and whatnot is out of the question. Let's focus on a simple world where there's no air friction, cows are perfect spheres, and whatnot. In this hypothetical world, every bot sends a User-Agent header explaining who they are to the service they are sending.
In this hypothetical world, let's say you run a bot named Mimi that you want to use to crawl all of the websites for the coffee shops in your local area. By default the bot's User-Agent will look something like this (depending on what language and framework your bot uses):
Go-http-client/1.1
python-requests/2.25.0
Being a well-behaved netizen, you make up a user agent kinda like this:
Mimi/v0.0.1 (+https://mimi.fakesite/docs/botinfo)
You figure that giving people documentation on how your bot works and what it does will make systems administrators less likely to block it.
When you make a request to a new domain, you're supposed to fetch the /robots.txt or /.well-known/robots.txt files to figure out what you're allowed to crawl. Here's an example robots.txt from arcjet.com:
User-Agent: *
Allow: /
This allows any User-Agent to crawl through any path on the website.
When reading this file, your bot code should match its User-Agent to anything specified in that file, then crawl anything you're allowed to or not crawl anything you're not allowed to. Say there's a website with a robots.txt file like this:
This means that any bot can crawl any path (as long as there's 4 seconds between requests), but not anything in the /private/ folder. You can also publish a sitemap.xml file that gives crawlers a list of articles so they don't have to laboriously click every link in order to find out what's available.
Oh wait, they banned Mimi? Darn. Perhaps your code didn't respect the Crawl-Delay setting in their robots.txt file or caused enough load/egress bandwidth that the administrator took action and shut it down. Sometimes the humans behind the bots really want access to your information anyways, so they just disregard the robots.txt file, lie about their User-Agent, or more.
How misbehaved bots actually work
So let's say you're on the defense from bots that you've banned via your robots.txt but they still scrape you anyways. This is basically an impossible problem to solve on just the User-Agent alone, but it's an insidious one because you think that it should be easy. Just block the offending User-Agent strings, right? It can't be that hard, right?
You'd be tempted to write a HTTP server configuration fragment that looks something like this:
if (goingToServe(/^Mimi.*$/)) {
dont();
}
And that would work at first. The annoying part comes in when facts and circumstances force you to add many more rules so you end up with something like this:
Homework assignment: Why is this bad from a theoretical computer science standpoint? Answer in the comments where you found this post!
Each rule you add needs to be evaluated one after the other in a single thread, meaning that combining with the fact that regex evaluation is surprisingly time-complex, by attempting to protect yourself from bots, you've accidentally caused a denial of service attack against yourself. All an attacker would have to do in order to stop you is just send a bunch of very small requests (they probably don't have to be bigger than a single packet). Then you're down and it's hard to even log into the servers to stop it because SSH stopped working. To say the least, this is not an ideal scenario.
Of course, this still accounts for bots that set their User-Agent to identify themselves. Most of the time the bots you want to prevent will not do that. They will set their User-Agent to match exactly what a browser says (made easier by the fact that Chrome and other browsers froze the User-Agent string a few years ago). This combined with the new Sec-CH-UA header requiring you to actually parse the string correctly by randomly shuffling the contents means that sniffing the User-Agent is just no longer viable in this reality, to the annoyance of systems adminstrators worldwide.
So I can just block IP addresses if they send too much traffic, right?
Another naïve approach to defending against these attacks is the idea that you can just block the IP addresses of the bots if they're sending too many requests. This also seems pretty simple and can usually be done in your HTTP server (or more likely in the firewall via something like fail2ban). If you block IP addresses in the firewall, the kernel usually has a pretty darn efficient data structure so that it can avoid as much computation as possible.
❗
Any time you see someone use the word "just" in relation to security topics, that's usually a sign that there's some core unstated assumption being made that probably won't scale with reality.
The main problem with this approach is that it assumes that the attacker only has one IP address. In a world where massive numbers of proxy servers can be had for free by scraping HTML tables on the internet, this also won't scale because your attacker can simply change IP addresses at will. I've personally seen cases where an attacker had over 16,000 addresses, one IP address per request. It was a nightmare to defend against. I ended up solving this by making the web server pretend to be a teapot, but that's a story for another day.
So then you go down the rabbit hole of filtering by the ISP for that IP address (okay, by the autonomous system advertising the IP address block your attacker is using), the type of organization the IP belongs to (education, business, residential), geographic based filtering, and DNS blocklists. Your notes slowly become less and less intelligible to other humans as you slowly are dragged down into the pits of hell.
Also keep in mind that residential proxy services do exist, and attackers will use them. Residential proxy services go as far as to pay people $30 per month to plug a random Raspberry Pi into their network so that they can use that hapless family's home IP address to resell their egress bandwidth at prices that would make AWS blush.
What if you didn't have to deal with that madness?
The main problem with a lot of the solutions and corporate products that claim to fix all this is that they give you some control over how they work through configuration files, kernel tooling, or ClickOps web panels, but at some point you hit the glass ceiling and just can't do more to hack around it without bypassing it and implementing it yourself.
Security is complicated, and by removing entire classes of problems from the equation, you can make more time for the more complicated problems when they become relevant.
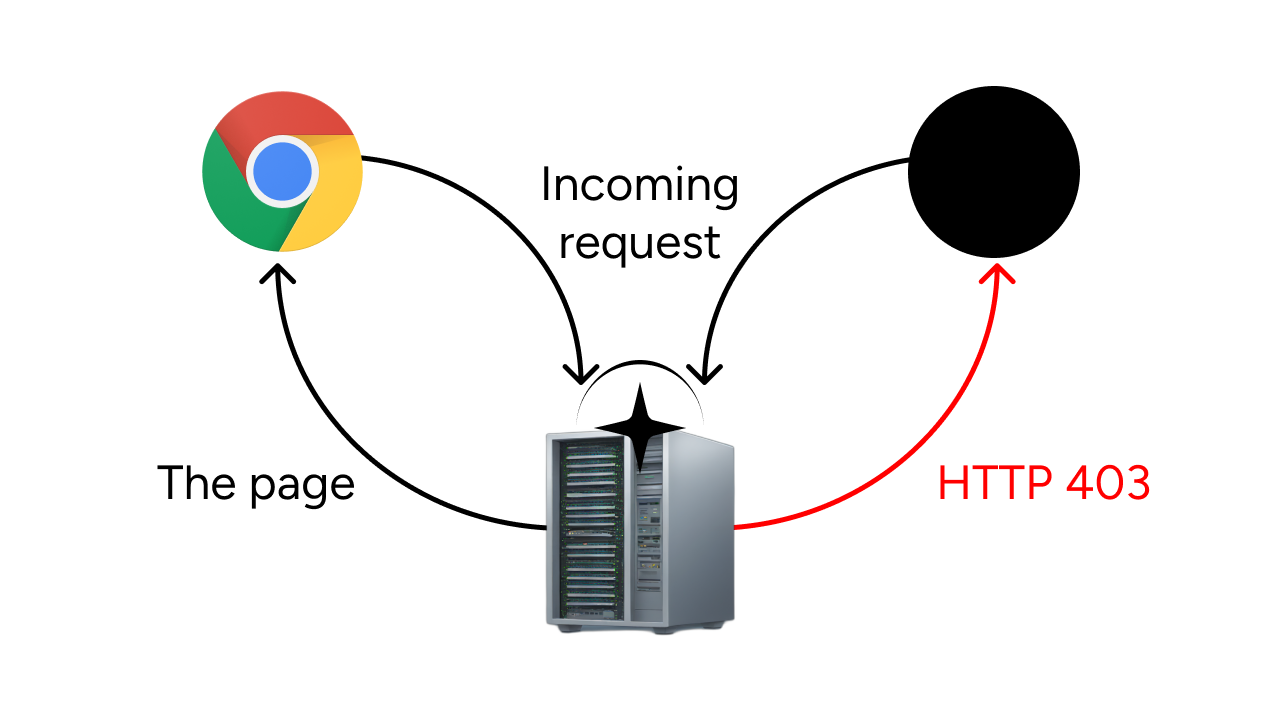
This is why Arcjet offers bot protection as part of the core of the tool. Imagine if blocking 80% of misbehaved bots was as easy as dropping a single file into your Next.js (or any other Node, Bun, Deno, or otherwise JS-related) project's source code:
// middleware.ts
import arcjet, { createMiddleware, detectBot } from "@arcjet/next";
export const config = {
// matcher tells Next.js which routes to run the middleware on.
// This runs the middleware on all routes except for static assets.
// You may want to adjust this to include your healthcheck route
// if your platform uses one. See https://regex101.com to test it.
matcher: ["/((?!_next/static|_next/image|favicon.ico).*)"],
};
const aj = arcjet({
key: process.env.ARCJET_KEY!, // Get your site key from https://app.arcjet.com
rules: [
detectBot({
mode: "LIVE", // will block requests. Use "DRY_RUN" to log only
// Block all bots except search engine crawlers. See the full list of bots
// for other options: https://arcjet.com/bot-list
allow: ["CATEGORY:SEARCH_ENGINE"],
}),
],
});
// Pass any existing middleware with the optional existingMiddleware prop
export default createMiddleware(aj);
That's it. Just drop that file into your code and you've blocked every bad bot except for search engines. If you want to allow more kinds of bots through your firewall (such as social link preview for apps like Slack, X, or Discord), all you need to do is add them to the allow list:
If you want even more granular control, you can check out the big list of bots to customize your rules further. You customize the compromises you want to make in code, where this configuration belongs. Configuration as code means that you review changes to the configuration as if they were changes to your code. No breach of the protocol to review ClickOps changes. To change the rules, just send in a pull request like you're used to.
Note that we don't just check the user agent. That would be silly. When Arcjet evaluates if something is a bot or not, it uses at least these bits of metadata to make a decision:
The User-Agent of the request, just to shave off the lowest-hanging fruit. This is checked entirely locally within your environment so that if there’s a hit, Arcjet can take a decision really quickly.
The IP address attached to the request (eg: is it a known bad actor?)
Information about the ISP behind the request (eg: are they in a country known for spambots or is this a commercial ISP that hosts budget servers?)
This allows Arcjet to make a lot more of an educated guess if an incoming request is from a bot or not.
Note that this is nowhere near perfect, but like I said before if you want perfect, you need a hole in the ground. Security is complicated, and by removing entire classes of problems from the equation, you can make more time for the more complicated problems when they become relevant.
That's what Arcjet is here to do: filter out 80% of the worst actors with 20% of the effort so that you can focus on the remaining issues if they become relevant. Sign up now to get going with Arcjet’s security SDK for developers.
Want to find out more about how Arcjet works? Check out our bot protection docs.
Google AI Overviews are causing fewer clicks for some site owners. If this is a fundamental shift in the web's traffic economy, how can site owners control where their content appears?
Bots now make up nearly half of all internet traffic - and many aren’t playing fair. Learn how to detect malicious crawlers, distinguish between AI agents, and defend your app using layered bot protection strategies like user-agent verification, fingerprinting, and rate limiting.