Bots now make up nearly half of all internet traffic - and many aren’t playing fair. Learn how to detect malicious crawlers, distinguish between AI agents, and defend your app using layered bot protection strategies like user-agent verification, fingerprinting, and rate limiting.
tl;dr: Bot traffic now dominates the web, and AI scrapers are making it worse. Blocking by user agent or IP isn’t enough. This post covers practical detection and enforcement strategies - including fingerprinting, rate limiting, and proof-of-work - plus how Arcjet’s security as code product builds defenses directly into your app logic.
Bots have always been a part of the internet. Most site owners like good bots because they want to be indexed in search engines and they tend to follow the rules.
Bad bots have also been a part of the internet for a long time. You can observe this within seconds of exposing a server on a public IP address. If it’s a web server you’ll quickly see scanners testing for known WordPress vulnerabilities, accidentally published .git directories, exposed config files, etc. Same for other servers: SSH brute forcing, SMTP relay attacks, SMB login attempts, etc.
But recently things seem to have become worse. Depending on who you ask, bots make up 37%, 42% or almost 50% of all 2024 internet traffic. This also ranges by industry, from 18% in marketing to 57% in gaming (2023).
Arcjet’s bot detection is our most popular feature and we see millions of requests from bots every day with all sorts of abuse patterns. In this post we’ll look at the problem bots cause, the techniques they use to evade defenses, and how you can protect yourself.
A human using a web browser has certain expected behaviors. Even if many requests to the various page assets can be executed in parallel, they will still make requests at human speed. Their progress will be gradual (they won’t load every page on a site simultaneously), and caching mechanisms (local in-browser and/or through a CDN) work to reduce the number of requests and/or data transfer.
Good bots mimic this behavior by progressively visiting site pages at a more human-like pace. They typically follow the rules posted by site owners (the robots.txt voluntary standard was first published in 1994 and became a proposed standard in 2022).
Problem
Description
Examples
Expensive requests
Bots request resource-intensive pages - from static HTML to dynamic pages backed by costly database queries. These pages often can’t be cached or pre-rendered.
Bots crawling every Git commit, blame, and history page on SourceHut. Dynamic content on online stores and wikis being repeatedly requested.
Large downloads
Projects hosting big files - like ISOs or software archives - suffer when bots download at scale, straining bandwidth.
Fedora Linux mirrors overwhelmed by bot downloads. Open source projects struggle with abusive scraping of images, documentation, and archives. Even large vendors like Red Hat and Canonical have to manage these loads; smaller projects rely on limited infrastructure or donations.
Resource exhaustion
Every request has a cost - whether for dynamic or static content. Bots can saturate compute, bandwidth, or memory limits, degrading service or creating DoS-like conditions.
LWN and Wikipedia fighting traffic spikes. Brute-force login attempts on mail servers (e.g., this case) seeking spam relays. Even generous hosts like Hetzner can’t handle infinite abuse; serverless (per request) pricing makes this even riskier.
Are AI bots worse?
Many recent scraping incidents have been attributed to AI crawlers. Attribution is tricky - user agents and IPs are easy to spoof - but detailed logs and traffic patterns from open-source platforms strongly suggest AI bots are a major contributor:
The Diaspora open source web infrastructure traffic logs show 24% of traffic from OpenAI’s GPTBot and 4.3% from Anthropic’s Claudebot. Around 16% come from Amazonbot, although it’s not clear if that is for AI or not.
ReadTheDocs posted examples of crawlers excessive download requests. The user agents weren’t listed, but applying Cloudflare’s AI crawler block list cut bandwidth by 75% - from 800GB/day to 200GB/day.
Discussions around bot traffic from KDE’s GitLab instance suggested traffic from “Chinese AI companies” did not include proper user agent identification whereas traffic from “Western LLM operators” did.
As with everything, incentives matter. Site owners are happy to serve Googlebot because its reasonable behavior means it doesn’t cost (much) and the site gets traffic from searches in return. Win-win. If you don’t want that, it’s easy to restrict or block with robots.txt.
Contrast this with AI where scraping is usually for training purposes with no guarantee that the source of that training data will ever be cited or receive traffic. Why would a site owner want to participate in this “trade”? They’re more likely to want to block the traffic, so the AI scrapers need to hide their identity.
Wildcard: agents acting on behalf of humans
Most site owners want human traffic, so the definition of good vs bad bots comes down to whether that automated traffic is acceptable or not. There’s a spectrum:
Automated API clients = good.
Search engine indexing bots = usually good.
AI crawlers = sometimes good or bad, depending on your philosophical stance.
Scrapers = bad.
This becomes more challenging when you introduce AI agents acting on behalf of humans. The difficulty is nicely illustrated by the type of bots OpenAI operates:
Crawler used to collect training data for foundation models.
✅
❌ Provides no return value to the site owner.
User agent is documented and can be blocked via robots.txt. High bandwidth and content costs.
(Operator)
Full browser agent (Chrome in a VM) used by OpenAI agents to interact with the web on user request.
❓
❓ Depends on use case - behaves like a human user.
No public documentation on how to identify it. Mimics normal Chrome user traffic. Cannot be reliably blocked without false positives.
As AI tools become more popular, simply blocking all AI bots is probably not what you should do. For example, allowing AI bots that act more like search engines such as OAI-SearchBot, means your site will receive traffic from users displaced from the traditional search engines.
Distinguishing between different areas of your site is also important. You should allow search indexing of your content, but block automated bots from a signup page. This is what the robots.txt is supposed to be for, but using a bot detection tool like Arcjet with different rules for different pages of your site allows it to be enforced.
Operators like OAI-SearchBot offer value (e.g., traffic, citations). Others, like GPTBot, provide no benefit and can impose high costs. Treat each agent class differently. Blocking all AI bots is a blunt instrument.
How to detect and block bots
The first step to detecting and managing bots is to create rules in your robots.txt file. Good bots like Google will behave and follow these rules. It’s a good exercise to develop an understanding of how you want to control bots on your site. Use Google’s documentation to guide creating the rules.
But we have to assume that the bad bots won’t follow these rules, so this is where we start to build layers of defenses. Start with low-cost signals (headers), then move to harder-to-spoof data (IP reputation, TLS/HTTP fingerprinting), and finally consider active challenges (CAPTCHAs, PoW).
Blocking user agents
A surprising number of bad bots actually identify themselves with the user agent HTTP header. We often see requests identified as curl, python-urllib, or Go-http-client from simplistic scrapers that haven’t changed the default user agent. We track many hundreds of known user agents in our open source well-known-bots project (forked from crawler-user-agents).
New crawlers and bots are released all the time. As we saw above, OpenAI has at least 3 bots, plus its Operator agent, and Anthropic has changed the name of its bot multiple times. Keeping up with the latest user agent variants is time consuming.
Clients can set the user agent header to whatever they like and can pretend to be something else. The User-Agent header should be set for every HTTP request and it has a specific format, but there is no enforcement of this. If you want to allow GoogleBot, a bad bot could pretend to be Google by using the same user agent header.
Arcjet’s rule configuration allows you to choose specific bots to allow or deny and use categories of common bots, which get regularly updated. This means bot protection rules can be granular and easy to understand. For example:
const aj = arcjet({
key: process.env.ARCJET_KEY!, // Get your site key from https://app.arcjet.com
rules: [
detectBot({
mode: "LIVE",
// Block all bots except the following
allow: [
"CATEGORY:SEARCH_ENGINE", // Google, Bing, etc
// Uncomment to allow these other common bot categories
// See the full list at https://arcjet.com/bot-list
//"CATEGORY:MONITOR", // Uptime monitoring services
//"CATEGORY:PREVIEW", // Link previews e.g. Slack, Discord
],
}),
],
});
Verifying user agents
To mitigate spoofed requests where a client pretends to be a bot we want to allow, you need to verify the request. For example, if we see a request with a GoogleBot user agent, we need to verify that request is actually coming from Google.
The big crawler operators all provide methods for verifying their bots e.g. Applebot, Bing, Datadog, Google, and OpenAI all support verification. This is usually through a reverse DNS lookup to verify the source IP address belongs to the organization claimed in the user agent. Some provide a list of IPs which then need to be checked instead e.g. Google has a machine readable list of IPs.
Example: Verifying Googlebot
To check if a request is coming from a Google Crawler:
1. Run a reverse lookup on the client source IP address. For example, a request from 66.249.66.1 claiming to be Google using the host command on macOS or Linux. Check that the domain result is either googlebot.com, google.com, or googleusercontent.com:
~ host 66.249.66.1
1.66.249.66.in-addr.arpa domain name pointer crawl-66-249-66-1.googlebot.com.
2. Run a forward DNS lookup on the domain returned and check that the IP address matches the original source IP address:
~ host crawl-66-249-66-1.googlebot.com
crawl-66-249-66-1.googlebot.com has address 66.249.66.1
We can see that the IP address matches the source IP, so we know that this request is actually coming from Google.
IP address reputation
As you receive requests from a variety of IP addresses, you can build up a picture of what normal traffic looks like. This technique has been used to prevent email spam for decades - the same principles apply when analyzing suspicious web traffic. If an IP address has recently been associated with bot traffic then it’s more likely that a new request is also a bot.
Various commercial databases exist from providers like MaxMind, IPInfo, and IP API. They offer an API or downloadable database of IPs with associated metadata like location and fraud scoring.
Looking up IP data like the network owner, IP address type, and geo-location all help to build a picture of whether the request is likely to be abusive or not. For example, requests coming from a data center or cloud provider are highly likely to be automated so you might want to block them from signup forms. Cloudflare reported that AWS was responsible for 12.7% of global bot traffic in 2024 and Fedora Linux was forced to block all traffic from Brazil during a period of high abuse.
IP data isn’t perfect though. IP geo-location is notorious for inaccuracies, especially for IP addresses linked to mobile or satellite networks. Bot operators cycle through large numbers of IP addresses across disparate networks, and are buying access to residential proxies to mask their requests.
IP-based decisions often cause false positives, so blocking solely on IP reputation is risky. Arcjet’s bot detection provides all the signals back into your code so you can decide how to handle suspicious requests e.g. flagging an online order for human review rather than immediately accepting it.
The usual approach is to trigger a challenge, like a CAPTCHA. Early versions relied on distorted text that was difficult for OCR (Optical Character Recognition) software to parse. More recent iterations include "no-CAPTCHA reCAPTCHA" (which analyzes user behavior like mouse movements before presenting a challenge) and invisible CAPTCHAs that work in the background or require showing “proof of work”.
Proof of work
Requiring all clients to spend some compute time completing a proof of work challenge introduces a cost to every request.
This idea isn’t new. Bill Gates famously announced a similar idea back in 2004 in response to huge volumes of email spam. The theory is that an individual human browser can afford to spend a micro-amount of time solving a challenge, whereas it would make mass web crawling economically inefficient. The challenge difficulty could increase depending on how suspicious the request is, making it increasingly expensive for bots.
There are several open source projects which implement this idea through a reverse proxy that will challenge all requests to your site: Anubis, Checkpoint, go-away, Nepenthes, haproxy-protection, and Iocaine are all interesting implementations.
The effectiveness of these types of proof of work or CAPTCHAs is an ongoing arms race. Modern AI can now solve many types of CAPTCHAs with increasing accuracy and speed. This means that while CAPTCHAs can deter simpler bots, determined attackers can bypass them, especially for high-value targets where the cost of solving the CAPTCHA is negligible compared to the potential profit. For example, paying a few cents (or even tens of dollars) to solve a challenge protecting sports or concert ticket purchases is worth it when the profits are in the hundreds of dollars.
HTTP message signatures
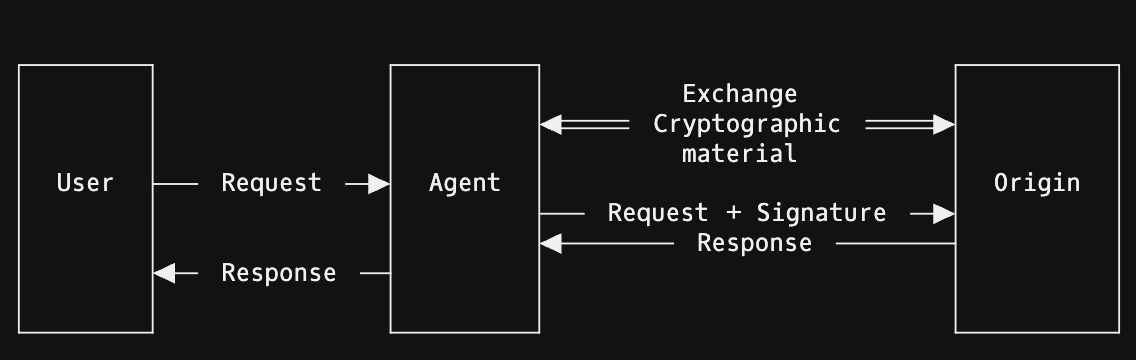
Cloudflare has proposed a new signature verification technique where bots can identify themselves using request signing. Whilst there are some benefits like non-repudiation, it remains to be seen how this improves the existing approach to verifying bot IP addresses using reverse DNS.
HTTP Message Signatures for automated traffic Architecture.
JA3/JA4 fingerprint
The JA3 fingerprint was invented in 2017 at Salesforce. It’s based on hashing various characteristics of the SSL/TLS client negotiation metadata. The idea is that the same client will have the same fingerprint even if it is making requests across IP addresses and networks. JA3 has mostly been deprecated because of how easy it is to cause the hash to change just by making slight changes to network traffic e.g. reordering cipher suites. It has been replaced by JA4.
The challenge with JA4 hashing is how it's based on the TLS handshake metadata, such as the protocol version and number of ciphers. This is available if you run your own web servers, but not on modern platforms like Vercel, Netlify, and Fly.io because they run reverse proxy edge gateways for you (Vercel calculates the JA3 and JA4 fingerprints for you and adds headers with the data).
JA4: TLS Client Fingerprint
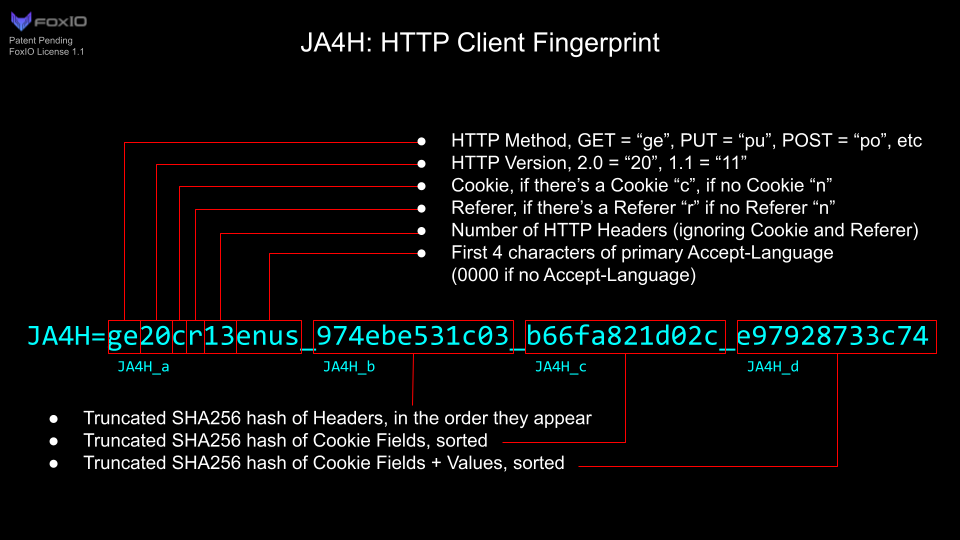
An alternative is JA4H which is calculated based on HTTP request metadata, but this is a proprietary algorithm whereas JA4 is open source.
When you have the hash there is still manual work to decide which ones to block just like deciding to block IP addresses. It is best combined with IP reputation when taking automated decisions so as to minimize the risk of false positives.
JA4H: HTTP Client Fingerprint
Rate limiting
IP address based rate limiting is a basic solution which, like user agent blocking, can help with some of the simpler attacks. However, it is easily bypassed with rotating IP addresses. Using different characteristics to key the rate limit can help - a session or user ID is the best option if your site requires a login.
Otherwise, using a fingerprint (like JA3/JA4) will help manage anonymous clients. Using compound keys that include features such as the IP address, path, and fingerprint as supported by Arcjet’s rate limiting functionality can help create sophisticated protections.
Conclusions
No one technique is enough because bot detection isn’t perfect. Instead, a robust defense strategy relies on a multi-layered approach. Starting with robots.txt to guide well-behaved bots is a good first step, but it must be augmented by more assertive techniques. These include verifying user agents, leveraging IP address reputation data, employing TLS and HTTP fingerprinting like JA3/JA4, implementing intelligent rate limiting, and considering proof-of-work challenges or CAPTCHAs where appropriate.
The key is to remain vigilant and adapt. Understanding the different types of bots, their evasion techniques, and the array of available countermeasures allows site owners to make informed decisions. Or use a product like Arcjet which takes away a lot of the hassle and means the protections are built right into the logic of your application.
Google AI Overviews are causing fewer clicks for some site owners. If this is a fundamental shift in the web's traffic economy, how can site owners control where their content appears?
We're adding more detailed verification options for developers where every request will be checked behind the scenes using published IP and reverse DNS data for common bots.