We live in the age of constant network traffic to web applications. Search engine bots, third party scrapers, automated security scanning, malicious attackers, and legitimate users hitting our web applications - the challenge is distinguishing between each of these.
Volume causes more problems: a bad behaving bot looks similar to someone making a large number of legitimate requests. With system availability being a key metric for contractual SLAs, mistakenly blocking a paying customer could be more financially disastrous than allowing a DoS attack to run its course.
Edge protections such as network firewalls, rate limiting, and Web Application Firewalls (WAFs) try to distinguish between friend and foe, but they can be fooled. How do you know if the traffic is legitimate? The presence of headers such as authentication keys and cookies are helpful, but how do you validate them?
Approach 1: IP Address
A simple approach to detecting Denial of Service (DoS) attacks is by the volume of requests coming from a single IP address. Certain metadata about the IP can also help, such as:
Reputation of the ASN (Autonomous System Number)
Reputation of the individual address.
Whether it is as a residential address, cloud host or VPN.
However, it's not uncommon these days for a malicious attacker to use proxy providers that have a range of residential connections, mobile network CGN (Carrier Grade NAT) and cloud hosted servers to hide their real IP address. These proxy providers also enable the fast rotation of IP addresses, which means every request could be coming from a different IP, bypassing rate limiting.
It's also not uncommon for real users to be using VPN services for added anonymity from their internet service providers. This causes problems if you're only relying on IP address data to detect malicious traffic.
A mobile proxy farm built for a commercial residential proxy service.
Approach 2: IP + User Agent
Since IP address alone is not enough, there are useful HTTP headers that can be analyzed for DoS attack detection. One of them is the User Agent header, which is defined by the HTTP client (such as browsers, programming languages and hacking tools) to identify itself to servers.
By parsing the user agent header, servers can determine if the request is coming from a desktop browser, a mobile phone, command line tools such as curl and wget, or security scanning tools like ffuf or gobuster.
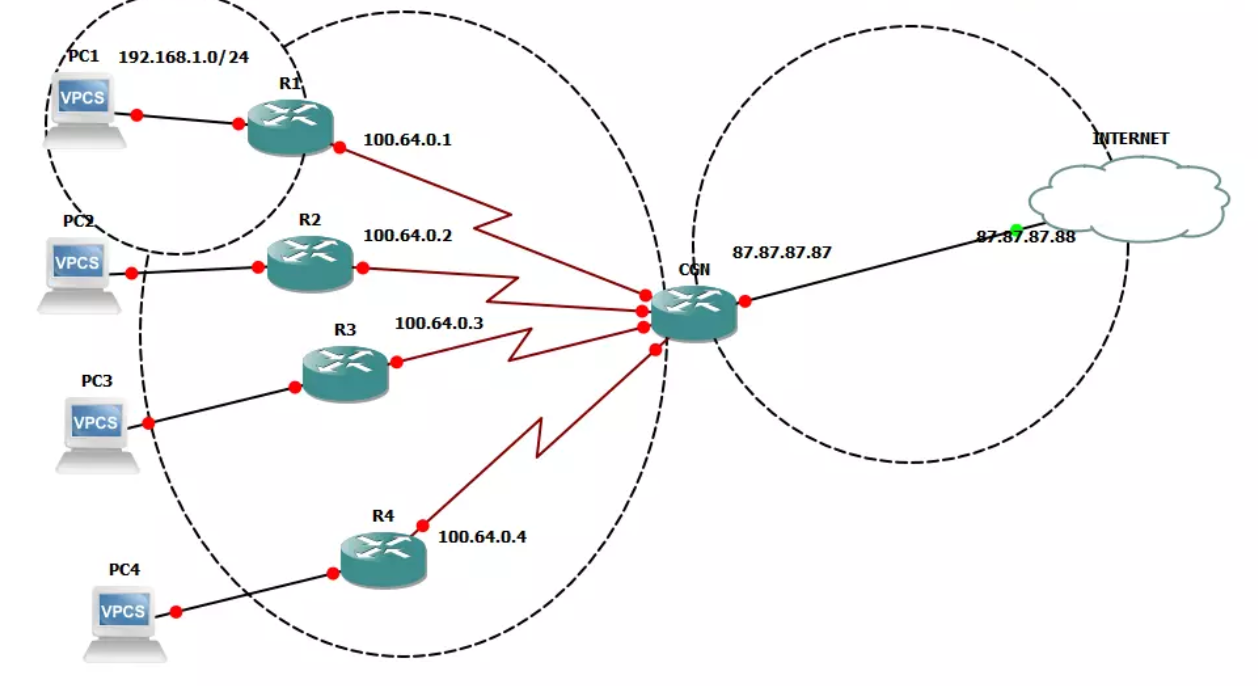
A Carrier Grade NAT Network, where many local networks share the same external IP.
Combined with the IP address, the user agent might paint a more accurate picture of individual clients, especially within shared IP environments such as mobile network CGN (Carrier Grade NAT), VPNs and large corporate networks. Even if the attacker is using a rotating proxy, their user agent might stay the same between requests.
The problem with the user agent header, however, is that it's untrusted user input. Anyone can specify any arbitrary user agent field in their HTTP request, and if they choose random agents for each request with a different rotating IP, they can effectively bypass this detection.
Attackers can also choose to use controlled, headless browsers (such as Puppeteer and Selenium) to mount attacks, which when residential proxies are used, makes them indistinguishable from a real user.
Approach 3: Characteristics Fingerprinting with Application Context
The layer that is best at distinguishing between a high volume customer and a real DoS attack is the application layer. This is because the application typically has more context on the traffic and users. The application can use session tokens to identify users; allowing additional context on things like:
Whether the user is authenticated or anonymous.
The customer type and details.
The customer's payment plan.
How long the customer has been signed up for.
Typical usage of the application by this user.
Understanding the context of every request is crucial to developing custom protection logic. Different rate limits can be applied, protection levels can be adjusted based on trust levels, and different actions can be taken based on the signals sent back from the security decisions. For example, if the request looks suspicious, then you could trigger a re-authentication for the logged in user.
Limitations of Handling Traffic Analysis at the Application Layer
While analyzing traffic at the application layer offers more nuanced handling of requests, there are some limitations. The biggest one is that your application still receives traffic.
Network-based security products block high-volume attacks before they reach your application, whereas application-level security necessarily requires your code to execute in order to apply context-aware rules and customize responses. Though this increases traffic to your app, it enables more nuanced handling of requests, such as distinguishing between different user types or flagging specific behaviors.
This is where a split approach makes sense. All cloud providers offer foundational DDoS protection for free. For example, from AWS:
All AWS customers benefit from the automatic protections of AWS Shield Standard at no additional charge. AWS Shield Standard defends against most common, frequently occurring network and transport layer DDoS attacks that target your website or applications. When you use AWS Shield Standard with Amazon CloudFront and Amazon Route 53, you receive comprehensive availability protection against all known infrastructure (Layer 3 and 4) attacks.
Vercel provides automatic DDoS mitigation for all deployments, regardless of the plan that you are on. We block incoming traffic if we identify abnormal or suspicious levels of incoming requests.
With this baseline level of protection in place, you can focus on implementing application-level protections that integrate with your code.
Using Arcjet to Categorize Traffic
Since Arcjet integrates into your application and has access to that context, you can use it to perform fingerprinting of each client based on the characteristics of the request.
For example, you can pass the user's ID or hashed API key as an identifier as a fingerprint, and apply limits to all requests made by that user no matter which IP or device it's coming from.
Option
Description
ip.src
Client IP address
http.host
Request host
http.request.headers["<header_name>"]
Request header value
http.request.cookie["<cookie_name>"]
Request cookie value
http.request.uri.args["<query_param_name>"]
Request query value
http.request.uri.path
Request path
If the user ID is not available (such as when the client is unauthenticated), you can use a combination of characteristics such as request headers, cookies, queries or URL paths to fingerprint an unauthenticated client and apply the appropriate security rules.
For example, this is how you can use a combination of request helpers in Arcjet with Next.js (such as req.ip and req.nextUrl.pathname) to construct a fingerprint for the client inside a Next.js route (see the docs for examples for other frameworks):
// Get the user's ID if they are logged in, otherwise use
// request IP and path as a fingerprint
const user = await currentUser(); // Return user information
const fingerprint: string = user ? user.id : (req.ip! + req.nextUrl.pathname!);
// Get the ArcJet client and request a decision
const aj = await getClient();
const decision = await aj.protect(req, { fingerprint: fingerprint });
Modified fingerprint code snippet from the Arcjet Next.js 14 example app
Network level security rules are good for brute-force type attacks such as volumetric DDoS attacks, leaving you to define more sophisticated rules within your application logic.
For example, setting a different rate limit based whether the user is authenticated or not:
// Add rules to the base Arcjet instance outside of the handler function
const aj = arcjet.withRule(
// Shield detects suspicious behavior, such as SQL injection and cross-site
// scripting attacks. We want to ru nit on every request
shield({
mode: "LIVE", // will block requests. Use "DRY_RUN" to log only
}),
);
// Returns ad-hoc rules depending on whether the session is present. You could
// inspect more details about the session to dynamically adjust the rate limit.
function getClient(session: Session | null) {
if (session?.user) {
return aj.withRule(
fixedWindow({
mode: "LIVE",
max: 5,
window: "60s",
}),
);
} else {
return aj.withRule(
fixedWindow({
mode: "LIVE",
max: 2,
window: "60s",
}),
);
}
}
Setting a rate limit depending on whether the user is anonymous or logged in (see the full code). In this example the limit is hard coded, but it could also be loaded from the user session using a database config (see an example).
Conclusion
In a time when real customers use VPNs to run python scripts, and bots use residential proxies with headless browsers, network layer traffic such as IP addresses and user agents are insufficient to distinguish between high-volume real customer traffic and a DoS attack.
Application context is key to identifying real users and anonymous bots. Arcjet provides this along with the ability to customize client fingerprinting to your application's needs, bridging the gap between network layer DoS detection and application security controls.
The Arcjet Python SDK allows you to implement rate limiting, bot detection, email validation, and signup spam prevention in FastAPI and Flask style applications.
Announcing Arcjet’s local AI security model, an opt-in AI security layer that runs expert security analysis for every request entirely in your environment, alongside our Series A funding.