Arcjet brings security closer to your application by analyzing requests within the context of your route handlers or middleware. In contrast to network firewalls or CDN security, with Arcjet your application now has full knowledge of which security decisions were taken and why.
Integrating Arcjet into your application involves installing our SDK. This gives developers an interface for configuring rules, passes the request through for analysis, and then returns the result.
Arcjet rules are just code, which means you can adjust them dynamically, e.g. different rules for different users. Then you can use the results of the analysis in your application logic, e.g. request a user re-auth if they log in from an unusual IP address.
Intercepting every incoming request means Arcjet is the hot path for your application. One of our design principles is that Arcjet should not interfere with the rest of the application. It should be easy to install, must not add significant latency to requests, and should not require changes to the application’s architecture.
This post is about how we achieve that.
Local-first security
The first step to fast response times is processing as much as possible locally. Although your interaction with the Arcjet SDK is in JS, most of the analysis happens inside a WebAssembly module. We bundle this with the SDK, and it runs in-process without requiring any additional software like Redis or an agent.
WebAssembly’s secure sandbox is ideal for this purpose, as it provides near-native performance and isolates untrusted HTTP requests (read more about how we use WebAssembly).
If you configure a bot detection rule or pass an email address for verification, all the initial analysis is happening entirely locally. Arcjet executes close to your code but doesn’t interfere with it.
We then enhance the request with the full context of the rule execution results. You can accept our allow/deny conclusion or do more with the data.
The total overhead of this analysis is typically no more than 1-2 ms.
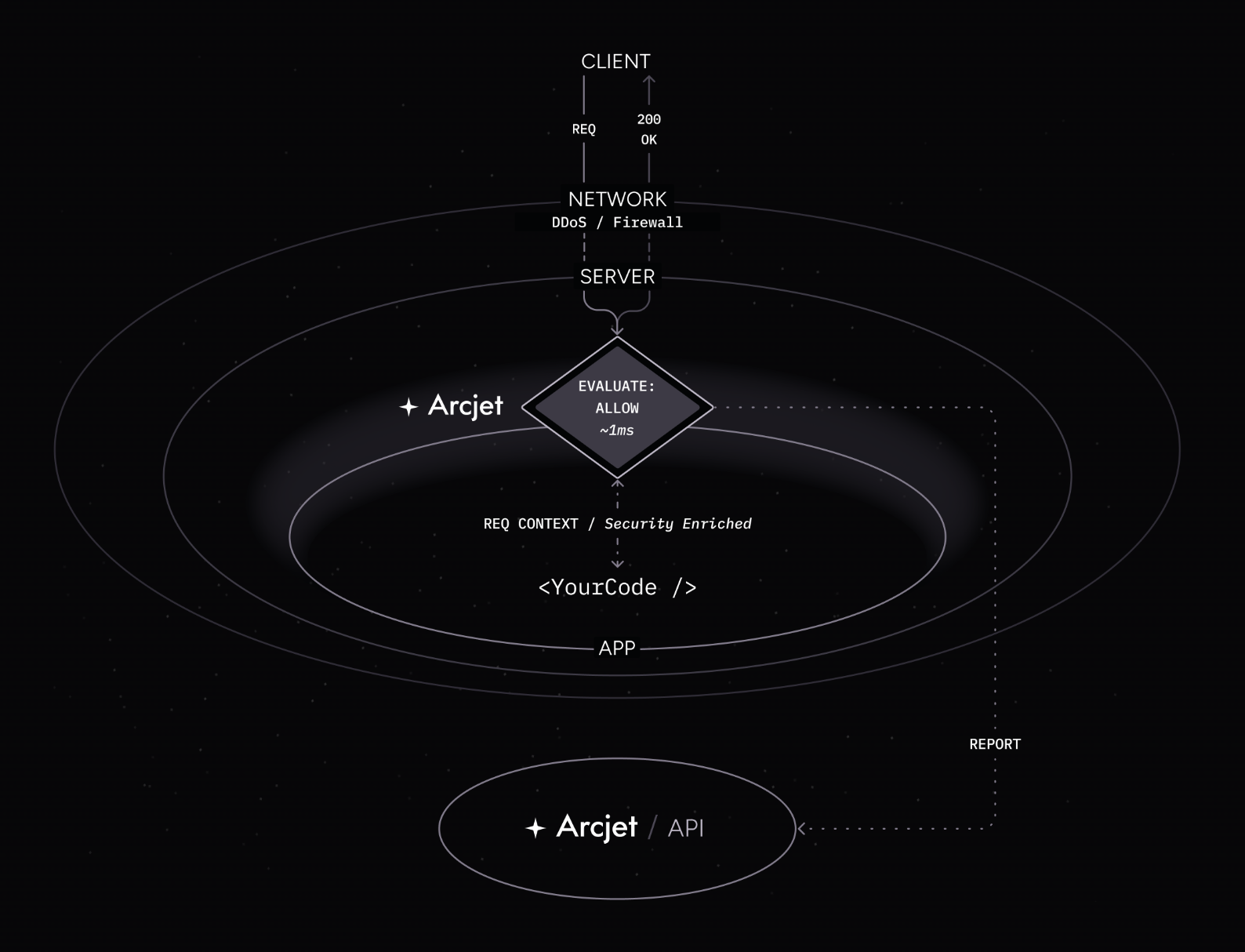
In this example, the Arcjet SDK is configured as middleware so it intercepts the request before it reaches your application code. Your platform applies standard DDoS protection through their network firewall. Most platforms provide DDoS protection transparently and out of the box for no extra cost. The request hits your server so Arcjet analyzes the request locally based on the rules you configured, then decides to allow the request. Arcjet returns the result and your application code continues to execute as normally.
A low-latency gRPC API in every cloud region
Not everything can be analyzed locally. Rate limits need to be tracked across requests, and we operate an IP reputation database that returns information like who owns the IP, geolocation data, and whether the IP is associated with a proxy, VPN, etc. For some rules like email verification, we do a network lookup to check if the domain is valid and it has MX records.
This is all handled via our API. If a decision can’t be taken locally, then our API will augment the analysis with a final decision. As this blocks requests to your application, we set ourselves a p95 latency goal of 20ms, with an additional few millisecond allowance for network latency.
We optimize for machines (but also consider humans) and aim for there to be no more than 1-2ms of network time between your app and our API. This means it needs to run in the same cloud region - we’re currently deployed to 22 different regions.
Calls to the Arcjet API are routed based on which cloud provider you’re hosted with. If you’re on AWS, then we use their Global Accelerator Anycast network. The SDK connects to the closest AWS edge location, and the traffic is forwarded to the nearest region. We use cross-zone application load balancers which will route requests to the best region based on service health and least load.
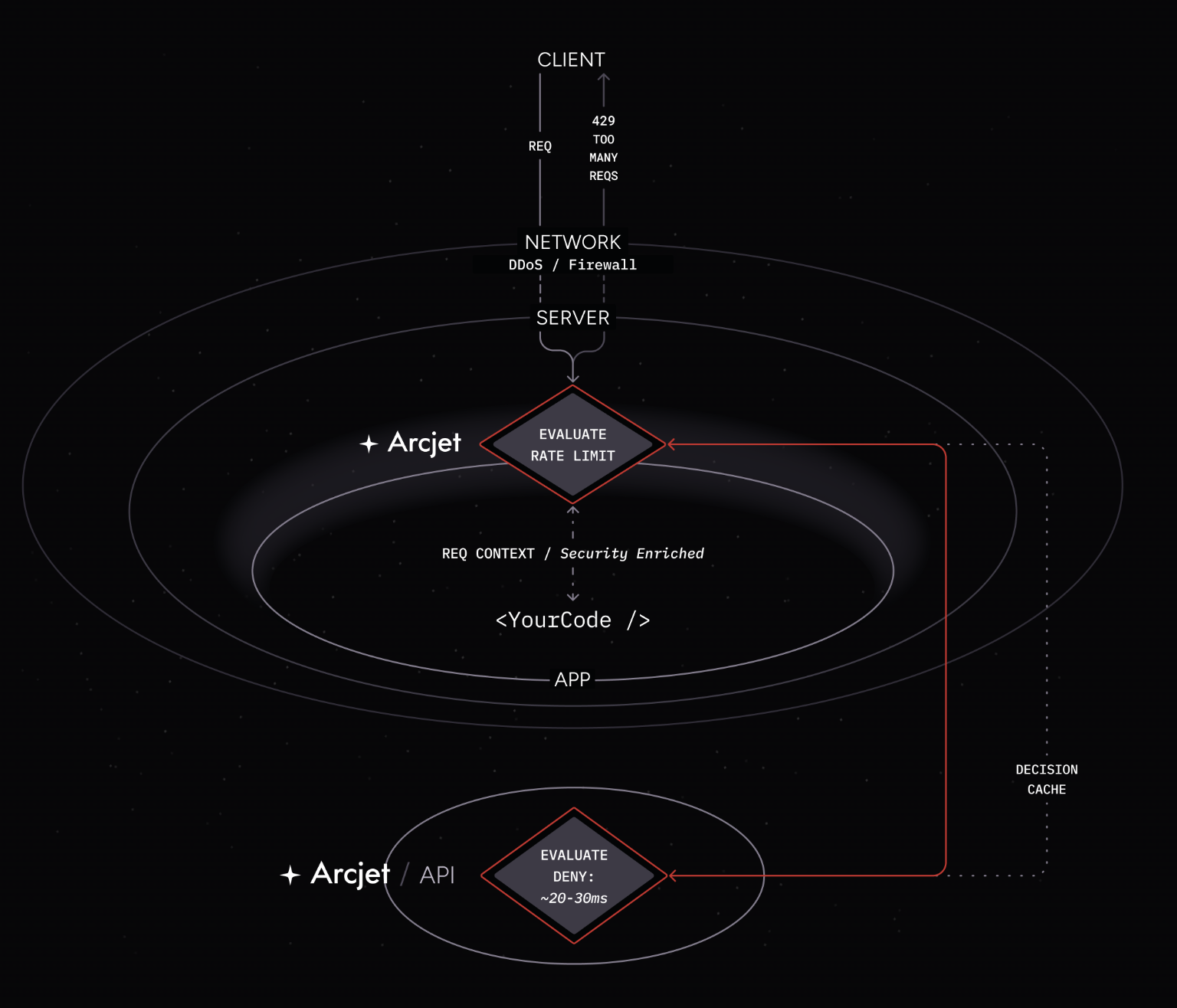
A client makes another request to your application with a rate limit rule configured. As before, the SDK passes the request context through to the Arcjet API which determines the limit has been exceeded. The SDK provides the details and your application code returns a 429 response to the client. The decision is also cached locally so that subsequent requests which match the rate limit rule do not need to rely on a call to the Arcjet API.
Persistent HTTP/2 connections
REST APIs are common for web services, but JSON is not the most efficient messaging format. It is too verbose and has parsing overhead. Instead, we use gRPC with Protocol Buffers (protobuf) as the interface description.
However, the slowest part of making a request is often establishing the initial connection. A normal TCP handshake requires 1 round trip, and the TLS handshake requires another 2. If a round trip takes just 1 ms, then that’s easily 3 ms taken up just opening the connection. Then the API request requires another round trip. Any network jitter and we're quickly hitting our allowed budget.
This is a particular problem for serverless environments where we want to avoid making a new request to our API every time your function is invoked.
A few months ago, we introduced support for multiplexing requests over a persistent HTTP/2 connection. When the Arcjet SDK is instantiated, we open a connection to our API and then keep that connection open over multiple requests.
The TCP and TLS handshake happens against the closest edge location (e.g. the AWS Global Accelerator edge or Fly.io edge), which minimizes the network time for each round trip. This is required for the first request, but the connection is maintained so the second connection flows over the already-open socket. This significantly improves performance.
Smart caching
If a client request is denied, then the chances are their next request should probably also be denied, but it depends on which rule caused the deny decision. This is where our smart caching comes in.
When an email verification request results in a deny, that should not be cached because it may be because the user made a typo. Their next request should be freshly re-evaluated.
But if it’s a rate limit rule that denies a request, we can look at the configuration to determine whether another request is going to result in another deny. Not only do we consider whether they are already over the rate limit, the time to cache the result is determined by the rate limit configuration. If the limit applies for a fixed window over the next 30 seconds, then we’ll cache for 30 seconds.
Caching is based on identifying the same client across multiple requests. The default way to do this is with an IP address, but that could easily change. That’s why we make it configurable so you can use your own identifier. If the user is logged in, then a session or user ID works well. An API key is another option.
This gets returned to the developer as part of the decision context so you can always inspect how the cache is working. For example, if you make a request and it’s denied due to a bot detection rule, you can see the TTL is 60 seconds:
You don’t have to do anything with this, but you could show the user how long they should wait to retry.
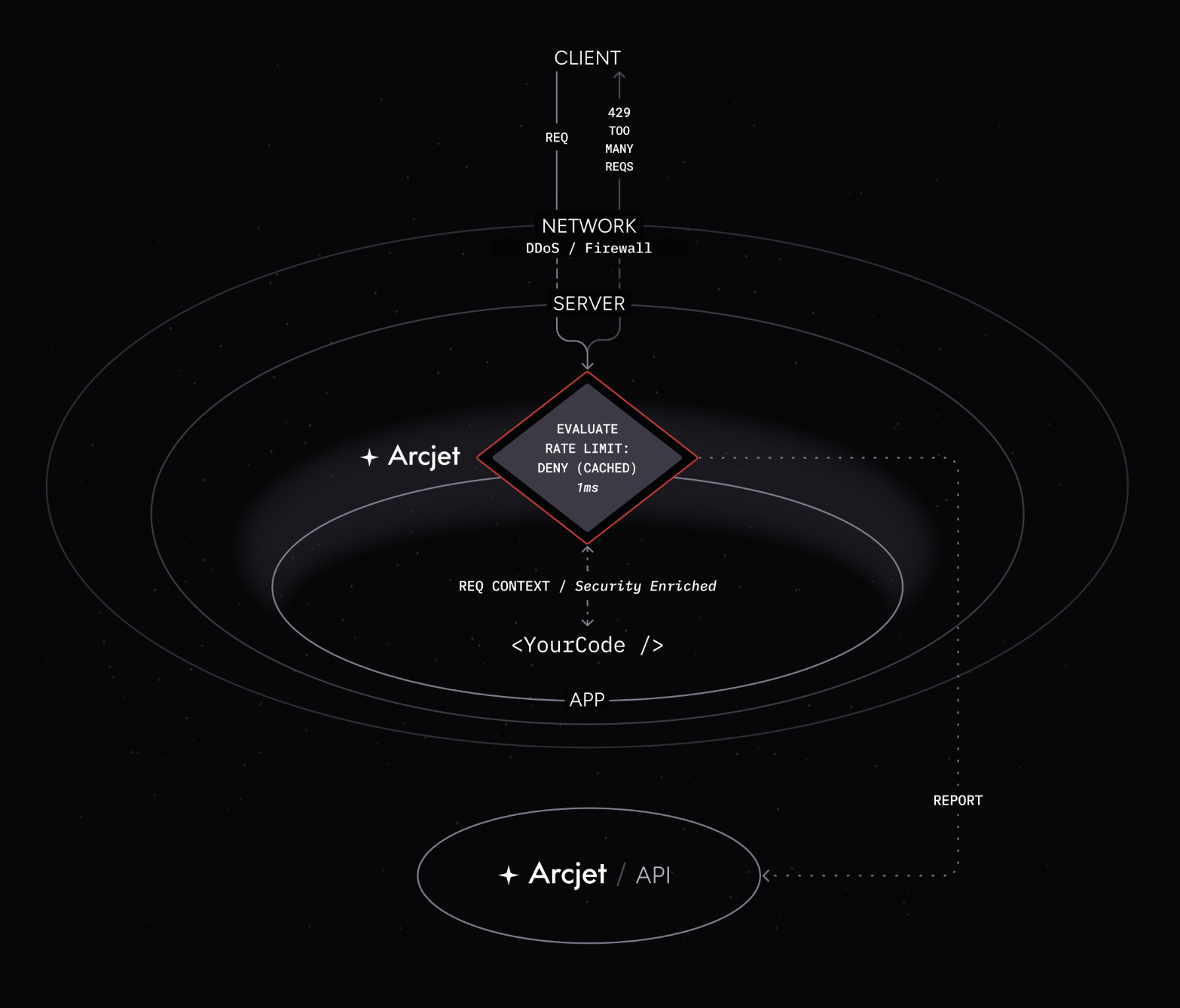
The previous deny decision is cached locally so that subsequent requests by the same client which match the rate limit rule do not need to rely on a call to the Arcjet API.
Results
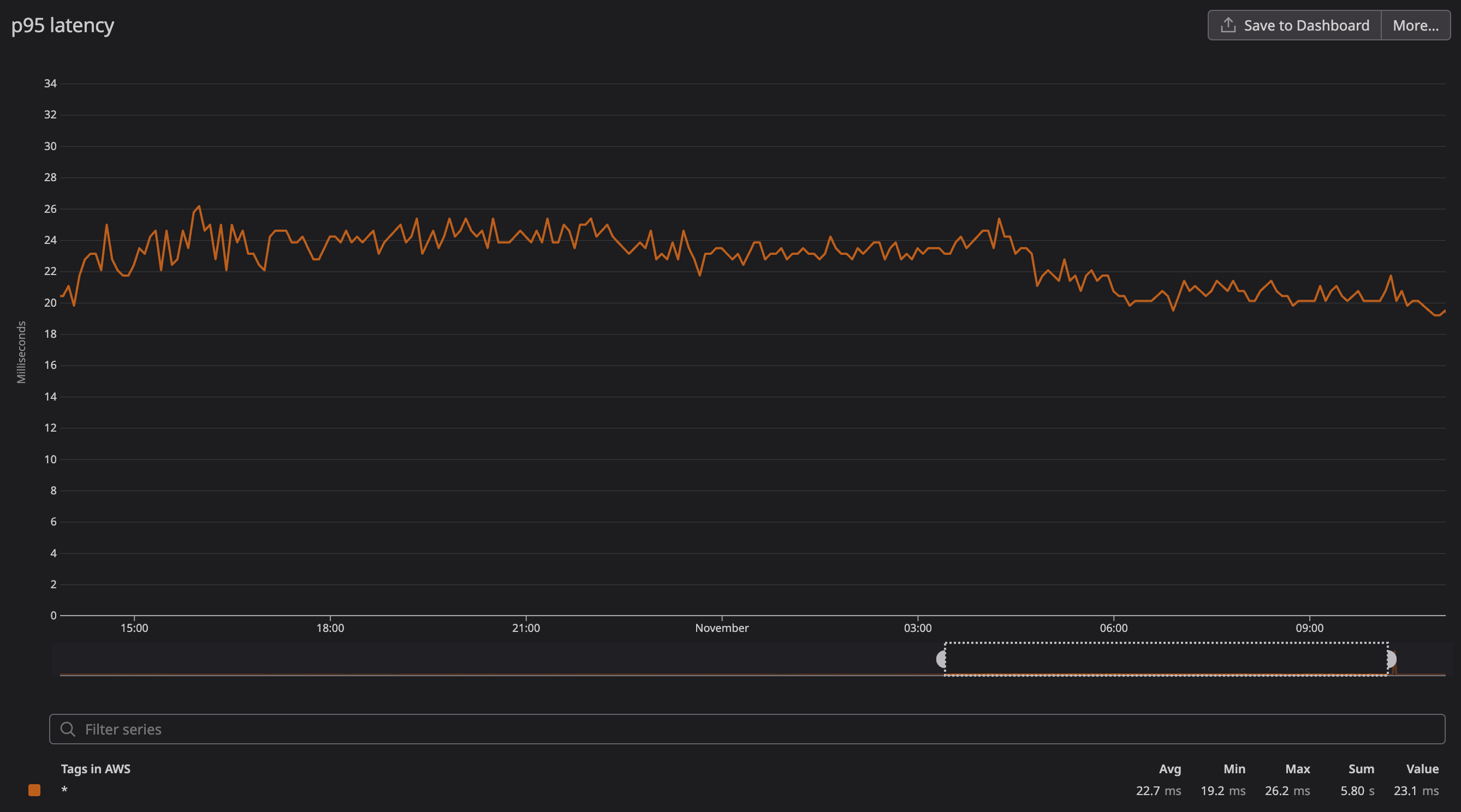
We continuously monitor API response time from the cloud regions we support. We use real API payloads to perform realistic analysis and alert when response times are out of range.
The result is our p95 API response time of around 25ms, which is within our goal range of 20-30ms. Our p50 is around 4ms, but we pay more attention to the outliers revealed by the p95 because those are what cause real user experience degradation.
We’ve spent a significant amount of time optimizing performance because we consider performance to be a key feature. There’s always more to do!
The Arcjet Python SDK allows you to implement rate limiting, bot detection, email validation, and signup spam prevention in FastAPI and Flask style applications.