Arcjet performs real-time security analysis of requests coming into your applications. It’s important to complete this analysis quickly to minimize the overhead, so we spend a lot of time on optimizing latency. The first part of this is to do as much analysis locally as possible which we achieve through a WebAssembly module embedded in our SDK. This usually returns a decision in less than 1ms.
However, we can’t always make a decision with local analysis alone. In these cases, we call our cloud API. The goal here is to return a decision within 20ms, including the full network round trip. That means we need to run our API close to where your application is.
Let’s say you’re a server and you live in the AWS US East 1 region in Virginia. If you’re talking to our API, the best place for it to be is right next to you in Virginia, ideally in the same Availability Zone (AZ). To quote AWS:
AZs are physically separated by a meaningful distance from other AZs in the same AWS Region, although they all are within 60 miles (100 kilometers) of each other. This generally produces single digit millisecond roundtrip latency between AZs in the same Region.
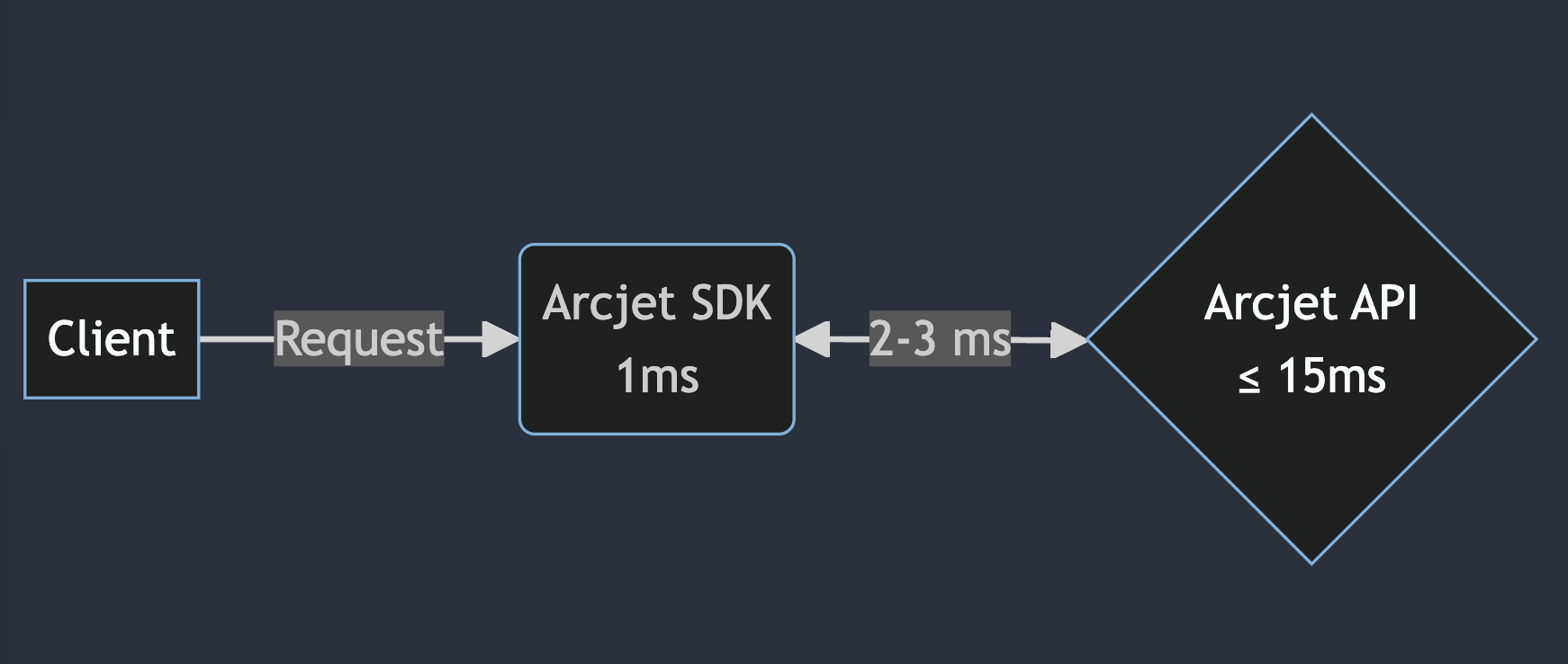
The best case scenario is that we have 1ms to complete any client-side analysis in our WebAssembly module, 2-3ms for the network round trip, and then ~15 ms to complete any API-based security analysis. That network round trip budget means we need to be in the same region as your application.
Flow diagram showing the ideal Arcjet SDK latency. A client connects to an app using Arcjet. The Arcjet WASM analyzes the request within 1ms. If an Arcjet API call is required, network latency is 2-3 ms, leaving ≤15 ms for the API to complete its analysis and return a decision.
Deploying to every AWS region
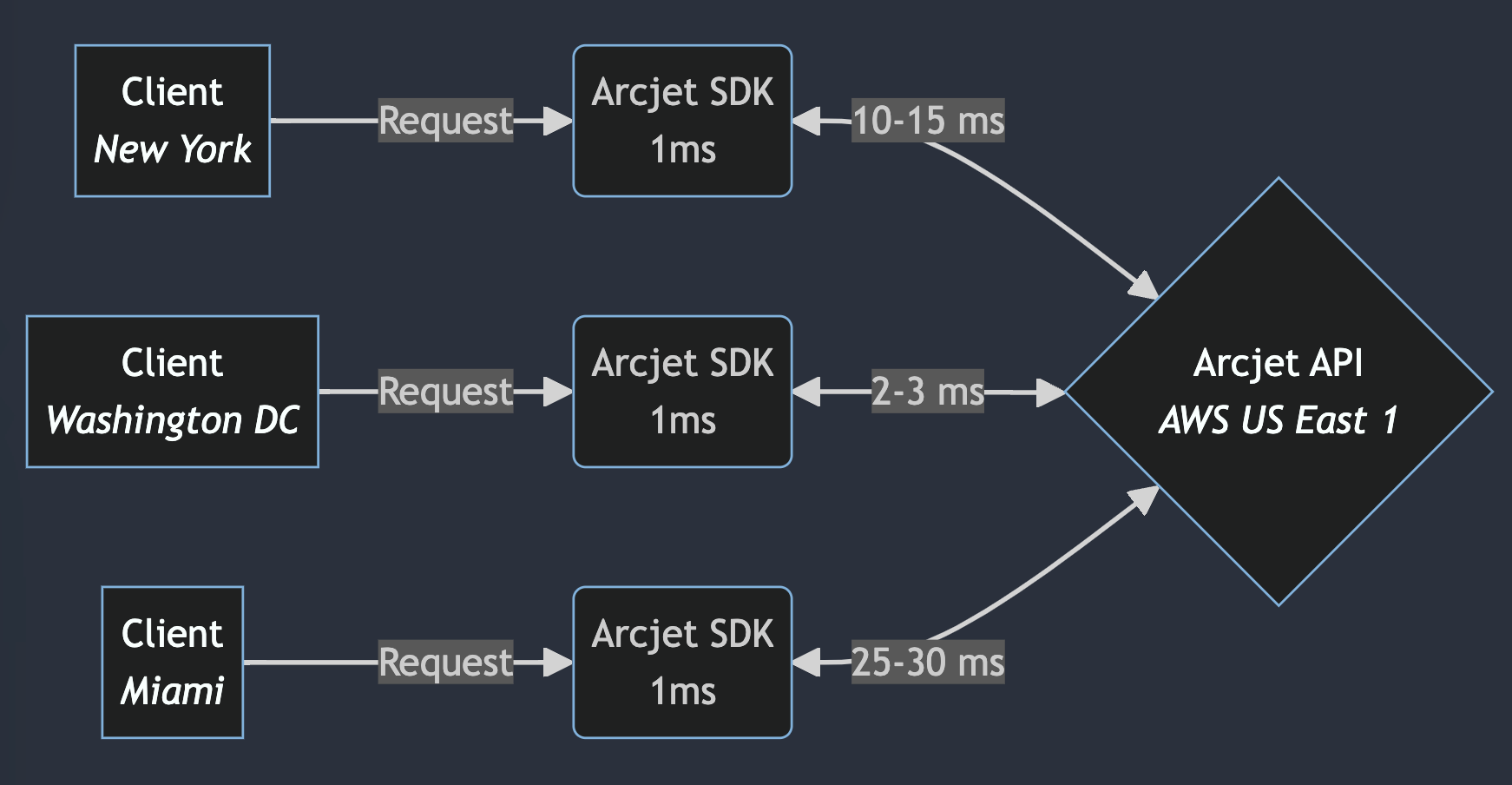
Deploying our API to every AWS region solves the problem of being close to your application. We use AWS Route53 latency based routing to direct traffic to the closest API endpoint. This continually monitors latency so it knows that if you’re in AWS US East 1 then your request should be serviced by the API endpoint also in AWS US East 1.
However, this doesn’t work very well if your API needs to be deployed outside AWS. From the AWS docs:
Data about the latency between users and your resources is based entirely on traffic between users and AWS data centers. If you aren't using resources in an AWS Region, the actual latency between your users and your resources can vary significantly from AWS latency data. This is true even if your resources are located in the same city as an AWS Region.
Why would we want to do that? Two reasons: 1) AWS might be the biggest cloud provider, but users deploy applications elsewhere; 2) we also have humans using our API.
Humans don’t live in data centers
If you’re a server living in a data center and want to connect to our API then the best place for that API is inside the same data center with you, but what if you’re a human?
One of the major differences between Arcjet and our competitors is that you can run Arcjet locally - your security rules get applied in the same way so you can test your security logic as you write code on your laptop. Of course, your laptop isn’t in a data center so if you live in New York you want the API to be as close as possible i.e. also located in New York.
The problem with New York is that land is expensive, especially if you’re a hyperscale cloud provider with huge data centers. That’s why AWS doesn’t have full regions in some places, like New York. They do cover some major locations like Frankfurt and Paris, and also have Cloudfront CDN locations in most major cities. However, in the US the full regions offering all services are far away from major cities e.g. US East 2 is in Ohio, US West 2 is in Oregon.
We can deploy to every AWS region and there are an increasing number of AWS Local Zones within major cities (although they are relatively expensive). Or we could find one or more providers who can give us compute services in major cities where AWS doesn’t have regions. In doing so, we introduce a multi-cloud problem and need to figure out how to route requests to the right location.
Flow diagram showing the Arcjet SDK latency when the Arcjet API is deployed to AWS US East 1. A client connects to an app using Arcjet. The Arcjet WASM analyzes the request within 1ms. If an Arcjet API call is required, network latency is varies depending on where the code is running because it all has to traverse the network to AWS US East 1.
Simple subdomains
When our service was solely deployed on AWS, Route53’s latency-based routing feature effectively directed requests to the correct region. However, this assumes that all instances are within AWS.
As we began testing our service for Fly.io users, we found that Route53 often routed requests to the wrong AWS region. Fly.io does not provide static outbound IP addresses, which complicates detecting the right region:
We don’t offer static IPs or regional IP ranges, and we discourage the use of our outbound IPs to bypass firewalls. A Machine’s outbound IP is liable to change without notice. This shouldn’t be a daily occurrence, but it will happen if a Machine is moved for whatever reason, such as a load-balancing of Fly Machines between servers in one region.
This meant that with Route53 DNS a machine running on Fly.io in Frankfurt might have its requests routed to our API in AWS US East 1 (Virginia) rather than AWS EU Central 1 (Frankfurt). This would cause high latency for Fly.io users.
Fly.io assigns each app a single address that accepts traffic across Fly.io’s global network and routes it to the closest running machine. For example, if a request originates from Frankfurt and there is a machine in Frankfurt, the traffic is routed there. If the closest destination machine is in Paris, it routes the traffic from the Frankfurt edge to the Paris destination instead.
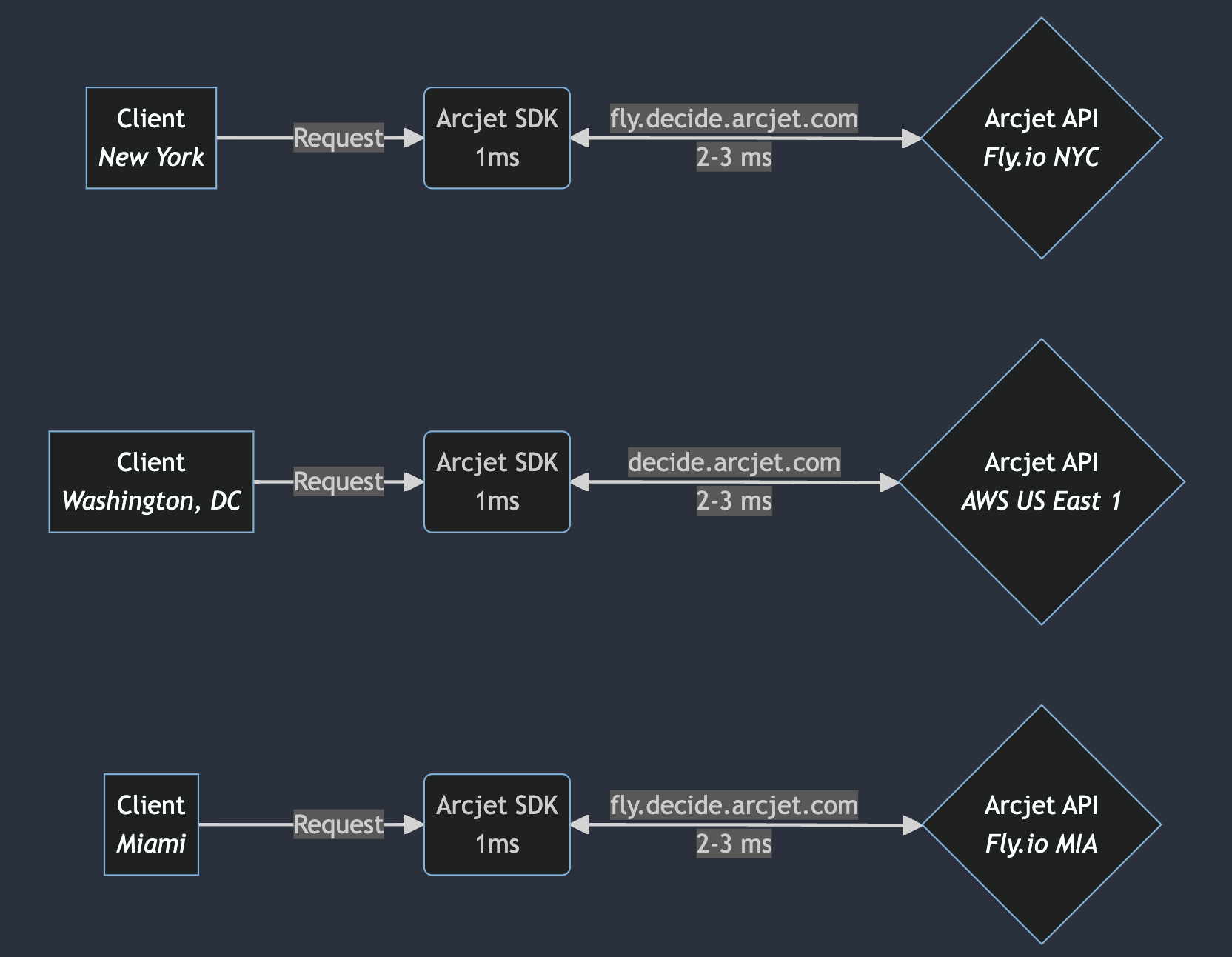
To send requests to the right provider, we set up a special subdomain pointing to our Fly.io address. Our AWS-hosted API remains accessible at decide.arcjet.com, while the Fly.io-hosted API is accessible at fly.decide.arcjet.com. Our SDK detects when it is running on Fly.io and selects the appropriate URL. Fly.io handles routing to the correct Fly.io API machine, whereas on AWS, we rely on Route53 for routing.
Flow diagram showing the Arcjet SDK latency when the Arcjet API is deployed to both AWS and Fly.io. A client connects to an app using Arcjet. The Arcjet WASM analyzes the request within 1ms. If an Arcjet API call is required, the SDK chooses the correct API endpoint depending on where it is running.
Anycast + proxy
Our compute requirements are straightforward: we just run containers, so we only need CPU and memory resources. We aim to deploy on commodity VMs across various platforms and avoid reliance on proprietary serverless platforms, which are not cost-effective for our API.
One option could be to continue using subdomains and detect which environment we’re in so the SDK can pick the right endpoint. Fly.io provides an environment variable to identify its platform, but detecting other platforms requires a different approach.
We could try to use metadata services provided by each cloud provider (e.g., GCP’s Metadata Server, Azure Instance Metadata Service, etc) to detect the current environment. This way, we could dynamically configure the application based on the platform it’s running on. However, that requires our SDK make external calls to probe the environment, which isn’t ideal.
As we scale to include more platforms, such as GCP, Azure, DigitalOcean, or Hetzner, we need a more scalable and automated solution. And for human users, we need to ensure they are directed to the closest node to minimize latency. This requires a smarter routing mechanism.
Anycast networking could solve the problem here. This is where a single IP address is shared by multiple destinations, and traffic is routed to the destination closest to the sender. As per Wikipedia:
Anycast is a network addressing and routing methodology in which a single IP address is shared by devices (generally servers) in multiple locations. Routers direct packets addressed to this destination to the location nearest the sender, using their normal decision-making algorithms, typically the lowest number of BGP network hops.
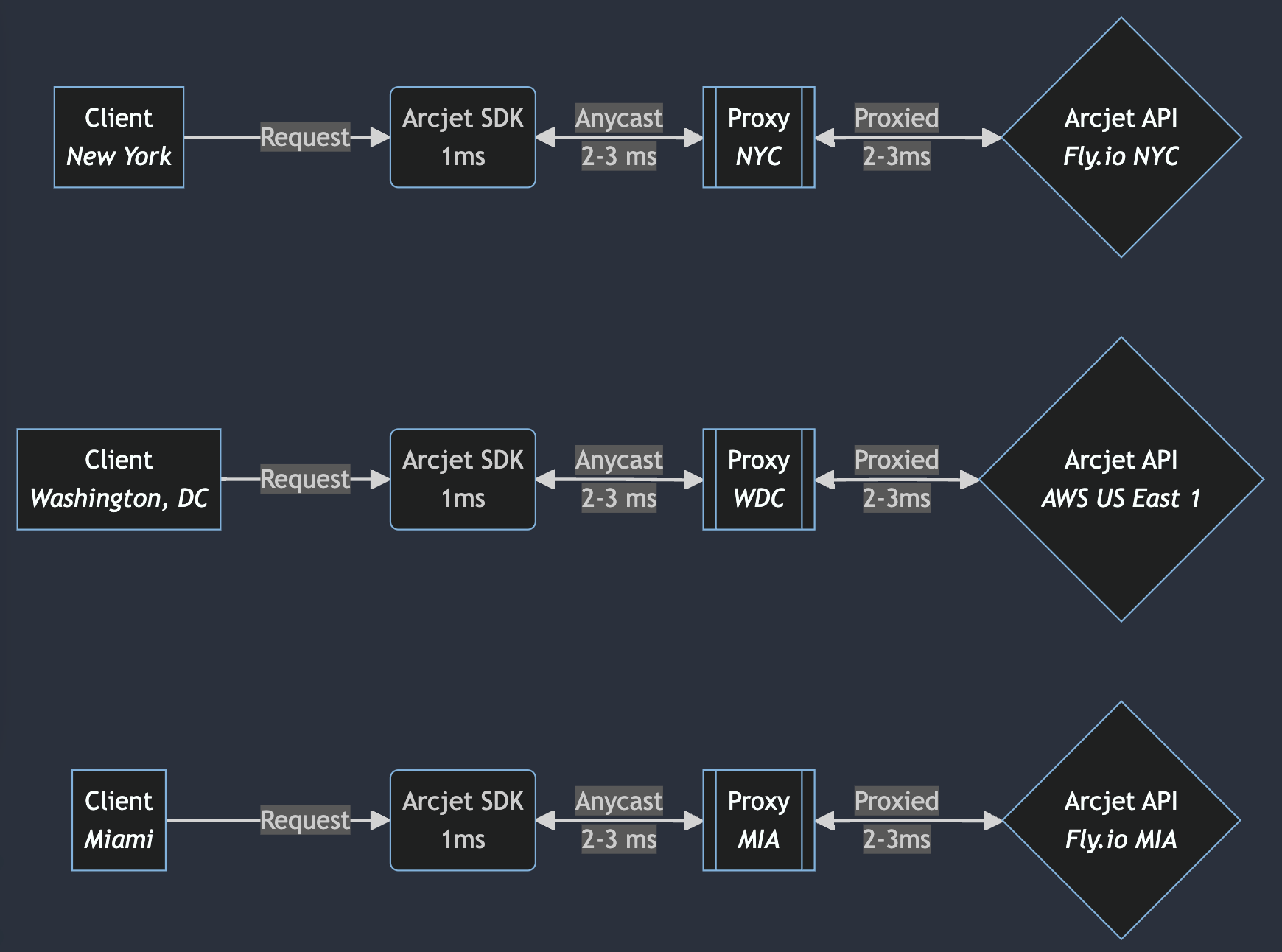
We could adopt a strategy similar to Fly.io’s global proxy, which routes requests to the closest healthy server. By deploying our own proxy nodes across a wide array of data centers, we can utilize Anycast IP addressing. Anycast allows the same IP address to be advertised from multiple locations, and incoming requests could then be routed to the nearest node based on network topology and health status.
If the closest node is Fly.io we’d send the request there. Likewise AWS. The request enters the network at the proxy which sends it to the relevant hosting provider behind the scenes.
Ideally we could we could have each provider announce our own IP range, so if the closest network is AWS the traffic would go there, but if it was Fly.io it would route there. This is known as multi-homing, but isn't recommended by AWS:
You must stop advertising your IP address range from other locations before you advertise it through AWS. If an IP address range is multihomed (that is, the range is advertised by multiple service providers at the same time), we can't guarantee that traffic to the address range will enter our network or that your BYOIP advertising workflow will complete successfully.
So we have to pick an independent network provider who has as many data center locations as possible, so the proxy can always be as close as possible to both the client and the backend data center.
Layer 7 proxying
Our API uses gRPC, which operates over HTTP/2 which is known as Layer 7 - the application layer. TLS termination occurs at the load balancer then HTTP requests are load balanced to our backend servers.
If we introduce a proxy in front of the AWS load balancer then it would take care of the TLS termination. To test this out, I chose Caddy because of how easy it is to set up, but for a real deployment Traefik may be more appropriate because of its advanced auto-discovery features.
Implementing the reverse proxy with Caddy involves configuring it to forward requests to our AWS Application Load Balancer (ALB):
{
# To make testing easier
debug
local_certs
}
decide.arcjet.com {
reverse_proxy https://name.us-east-1.elb.amazonaws.com {
header_up Host {host}
header_down Arcjet-Proxy-Latency {http.reverse_proxy.upstream.latency_ms}
transport http {
# Required because the ALB endpoint is different from the
# TLS server name on the certificate.
tls_server_name decide.arcjet.com
}
}
}
Caddyfile configuring a Caddy reverse proxy for an AWS Application Load Balancer (ALB).
Performance testing showed that running this setup on a virtual machine (VM) provider located near the AWS US East 1 region in Virginia introduced a 2-3ms overhead compared to accessing the AWS ALB directly. This overhead is primarily due to additional network hops introduced by the proxy and the inherent latency of the proxy itself.
Flow diagram showing the Arcjet SDK latency when the Arcjet API is deployed to both AWS and Fly.io. A client connects to an app using Arcjet. The Arcjet WASM analyzes the request within 1ms. If an Arcjet API call is required, the request is routed to the closest proxy using anycast. The request is then proxied to the closest backend.
Is layer 4 proxying an option?
An alternative to terminating SSL with Caddy is to proxy the TCP connection directly to the backend. Caddy has an experimental Layer 4 plugin that enables this functionality.
The primary difference between Layer 4 (transport layer) and Layer 7 (application layer) proxying is that the Layer 4 proxy forwards the entire TCP segment without interpreting the application layer data (e.g., HTTP headers). This proxying method is efficient for protocols that benefit from long-lived connections because the initial TCP and TLS handshakes are performed once, and the established connection is then proxied to the backend.
Services such as PostgreSQL or Redis are well-suited for Layer 4 proxying because they typically maintain persistent connections. In contrast, HTTP traffic usually involves short-lived connections, which can make Layer 7 proxying with TLS termination more efficient because the TLS handshake can be completed by the proxy closer to the client. This removes the need for additional network hops.
However, this dynamic changes when using techniques like HTTP keep-alive, upgrading HTTP connections to WebSockets, or leveraging HTTP/2 which supports multiplexing. These techniques allow multiple HTTP requests to be sent over a single, long-lived connection, thereby making Layer 4 vs Layer 7 proxying more a question of where you want to handle TLS termination and load balancing. You probably want to let the load balancer handle the connection and still distribute requests across your backend according to health and load, but that only works if you have distributed state management (or don’t care about state at all).
An alternative to Caddy is HAProxy which is a more mature and widely used solution which supports both Layer 4 & Layer 7 proxying. However, it’s written in C whereas Caddy is written in Go. As a company building modern security tooling, we try to avoid fundamentally (memory) unsafe languages!
Location matters
The fundamental goal is to minimize latency. The challenge is to position our infrastructure as close as possible to both major cloud providers and our human users in key metropolitan areas. Mismatches in location can introduce significant overhead and degrade performance.
Our tests demonstrated that in-region proxying adds minimal overhead. For instance, making a request to our API hosted in US East 1 from a VM in US East 1 via a proxy in the same region added only 2-3 ms of latency.
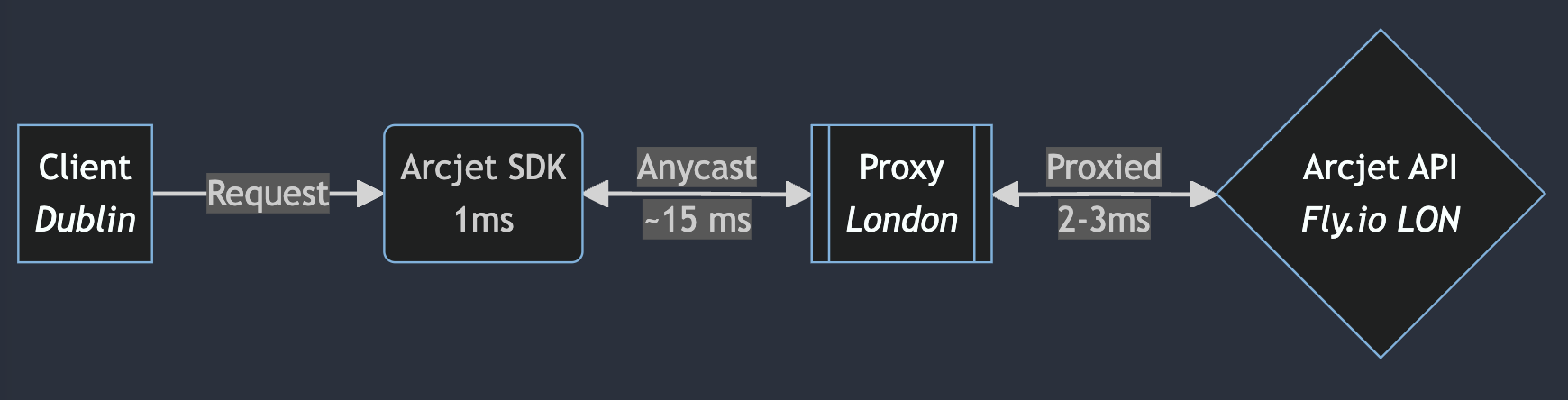
When we tested a less optimal configuration, the results highlighted the importance of geographic proximity. A request to our API hosted in EU West 1 (Dublin) from a VM in EU West 1 via a proxy in London introduced an additional ~15 ms of latency compared to a direct connection.
This is not surprising because the traffic has to go from Dublin to London and back, but it highlights the importance of matching proxy regions to API endpoint regions. Going over the public internet is unpredictable and subject to jitter and rerouting. Optimizations such as using an overlay network like Tailscale and provisioning dedicated network interconnections (such as AWS Direct Connect) are possible, but the physical distance is still the main constraint.
Flow diagram showing the Arcjet SDK latency when the Arcjet API is deployed to Fly.io in London via a proxy also in London. If the client is in Dublin then there is additional network latency.
Why bother?
The core issue revolves around the geographical location of our API endpoints. In the US, AWS regions are typically situated outside major cities. Proxying traffic from a client in US East 1 via a proxy in the same region back into AWS US East 1 can introduce unnecessary latency without providing any real benefit.
However, if a user is located in an area without a nearby AWS region but has other cloud providers closer, it would be better to route traffic to those closer providers. By deploying our API on multiple platforms and proxying traffic to the nearest endpoint, we could leverage the combined regions of both AWS and Fly.io to minimize latency.
This gets more complicated as we add providers. For example, AWS, Azure, Google, and Fly.io all have London regions, so how do we pick which one to send traffic from a client also in London? Does it even matter? Just pick one?
These are all questions we’re working on because we really care about minimizing latency!
Reducing WebAssembly bundle size: how Arcjet shrank its Rust bot detector 27% with Aho-Corasick, keeping per-request memory isolation and using Wizer snapshots.
How we designed the Arcjet CLI in Go as a stable, defensive interface for humans and AI agents: predictable commands, machine-readable output, strict validation, and confirmation before production changes.