When building an application I quickly end up wanting to log everything. Which functions are called with which parameters, complete database queries, the results of transformations… it’s not quite a REPL, but logging gives you a view into what your code is actually doing. Nothing new there.
Deploying to production is when the problems start to show up with this approach. The first is log volume - that’s why you have log levels. DEBUG in development and INFO in prod, with regular tweaks so you can see what’s going on with minimal noise. Again, nothing new.
But what happens when you have a tricky customer issue to investigate? INFO might not give you enough information and DEBUG is probably too much. How about enabling DEBUG for a particular customer?
If you have set up your logging properly then you will now have enough to figure out what’s going on. However, because you’re in production you’re also now logging customer data. This triggers a whole load of new problems.
Why not log everything?
First is privacy. Is there personally identifiable information in the logs? Did your privacy policy give you consent to use it for this purpose? How long is it stored for? What happens if you get a data access or erasure request?
Then comes security. If you’re logging everything then this could also include secrets, session tokens, API keys, and other data you really don’t want sitting around, especially if you keep your logs archived for a while. What if your logs leak or someone gains access to your logging system?
Arcjet is processing sensitive data on behalf of our customers so we’ve been spending time on both of these. Our whole mission is about helping developers protect their apps, so part of that is protecting our own!
Zap vs Slog
Until recently we were using the Zap logging library from Uber. This is a very popular structured logging library for Go which has various adapters that make it nicely extensible e.g. human readable in development, but JSON in production. Performance is also a key feature for our API because we're doing real-time request analysis, and Zap is known to be very fast. It’s been working well for us.
As of Go 1.21 there is now a structured logger (log/slog) built into the standard library and there is a growing ecosystem of tooling around it. slog is very similar to Zap in design - it’s called with a message, the severity level, and extra attributes attached as key-value pairs.
You can also easily set the default global logger without having to pass loggers around or add them to the context. This will be helpful as other libraries make use of it because they will then inherit your logging configuration.
Our goal is for each type to define which log fields need redacting as part of the type definition. The best time to consider field sensitivity is when the type containing the field is designed. That way developers don’t need to worry about what gets logged later.
Logging of potentially sensitive data should also follow an allow-list approach rather than a deny-list. That means newly added fields should not be logged by default so if anyone forgets to add a redaction tag it doesn’t mean the field gets logged in plain text by default - it simply doesn’t get logged at all.
Zap’s design for performance first makes implementing this complicated. I found an implementation in Caddy, plus discussion in zap#453 and zap#750, but it wasn’t straightforward once you go past anything more than a trivial fields.
For example, our internal Config struct is used to hold service configuration, including secrets. I wanted to log it on startup, but redact the secrets. Doing so required creating a custom zapcore.ObjectMarshaler (which is the documented way to redact fields).
// SecretConfig contains secrets. If logged with zap.Any this
// will be redacted, nut if logged as part of another struct
// using reflection-based encoding then it will be logged in
// plain text.
type SecretConfig struct {
// DBUrl is the connection string for the database
DBUrl url.URL
// CHUser is the username for the ClickHouse server
CHUser string
// CHPass is the password for the ClickHouse server
CHPass string
}
// MarshalLogObject implements the zapcore.ObjectMarshaler
// interface for the zap logger, manually adding each field
// so they can be redacted.
func (c SecretConfig) MarshalLogObject(enc zapcore.ObjectEncoder) error {
enc.AddString("DBUrl", fmt.Sprintf("**%s**", c.DBUrl.Host))
enc.AddString("CHUser", "**REDACTED**")
enc.AddString("CHPass", "**REDACTED**")
return nil
}
The main problem I found was that if the Config struct had other custom struct types, their ObjectMarshaler wouldn’t work - those additional structs would get converted to plain text. I ended up having to create a custom ObjectMarshaler on the top level Config struct which reflected all the fields and specifically excluded the secrets by field name, then added the object back so the ObjectMarshaler was called.
type Config struct {
// Port is the port to listen on
Port int
// SecretConfig is a struct of secrets separated so
// they don't get logged.
SecretConfig SecretConfig
}
// MarshalLogObject implements the zapcore.ObjectMarshaler
// interface for the zap object logger. It reflects all the
// fields, excluding the SecretConfig which is then added
// through a custom object marshaller. This redacts the fields.
func (c *Config) MarshalLogObject(enc zapcore.ObjectEncoder) error {
// Add all fields except SecretConfig
type configWithoutSecret struct {
*Config
SecretConfig interface{}
}
err := enc.AddReflected("Config", &configWithoutSecret{Config: c})
if err != nil {
return err
}
// Add SecretConfig with custom marshaller which will redact them
err = enc.AddObject("SecretConfig", c.SecretConfig)
if err != nil {
return err
}
return nil
}
This worked, but doesn’t give us a default allow-list style implementation. It’s only called once, but if it was in a performance-sensitive area of the code then reflecting would be slow.
Switching to slog for sensitive data redaction
A big reason to move to slog is the ease with which we can build field redaction with a custom LogValuer. This is the documented way to implement field redaction and, crucially, it supports nested structs that implement LogValuer themselves.
We don’t need to do anything for types without sensitive data - the default implementation will log all fields. However, where we have sensitive data then we implement our own LogValuer and list out all the fields to log.
// SecretConfig contains secrets. If logged with zap.Any this
// will be redacted, nut if logged as part of another struct
// using reflection-based encoding then it will be logged in
// plain text.
type SecretConfig struct {
// DBUrl is the connection string for the database
DBUrl url.URL
// CHUser is the username for the ClickHouse server
CHUser string
// CHPass is the password for the ClickHouse server
CHPass string
}
// LogValue implements slog.LogValuer and returns a grouped value
// with fields redacted. See https://pkg.go.dev/log/slog#LogValuer
func (o SecretConfig) LogValue() slog.Value {
return slog.GroupValue(
slog.String("db_url", fmt.Sprintf("**%s**", o.DBUrl.Host)), // Just show the host
slog.String("ch_user", "[redacted]"),
slog.String("ch_pass", "[redacted]"),
)
}
Adding a new field means it’s not logged unless you specifically add it to the LogValuer. This is a bit of extra work up front, but the allow-list approach means we don’t accidentally log something.
Why not use ReplaceAttr?
slog custom handlers can be given HandlerOptions which includes an option called ReplaceAttr. This can be used “to rewrite each non-group attribute before it is logged” and is a perfect place for redaction, except for two problems:
You must search for the fields you want to redact. ReplaceAttr receives the key so you can easily match your desired field names, but this is a deny-list approach. You are redacting fields just before they’re about to be logged rather than controlling the full logging output. If you add a new field, you need to remember to update ReplaceAttr. Appropriate for matching a general list e.g. always redacting fields named email or of a particular type (perhaps net.IP), but not what we’re looking for.
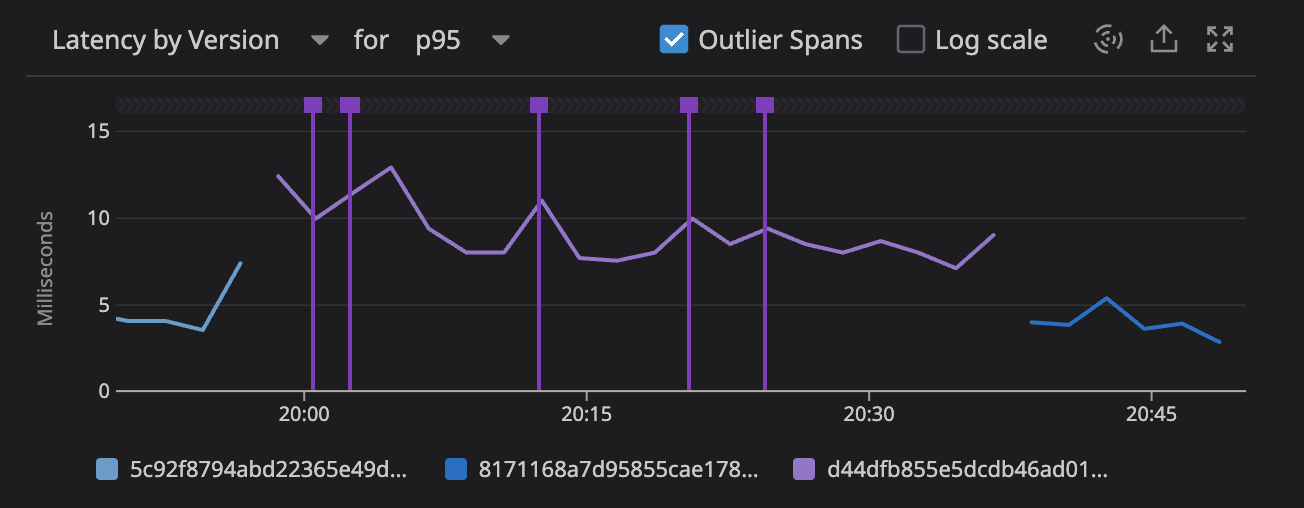
If you use reflection to look for struct tags you will incur a performance penalty. Depending on the nature of your application this may be acceptable, however our API has a very tight performance SLA. Using struct tags with a generic, reflection based method of redacting fields caused our p95 response time to jump from 4ms to 10ms, with some outliers higher than that.
Performance of slog vs Zap
Switching to slog has had no performance impact in production. We’ve improved developer experience by not needing to worry about sensitive fields being logged (once we’ve created the initial type) and have minimized the chance of a future mistake (from new fields or by accidentally increasing logging in production).
We also have a development philosophy of minimizing dependencies, so being able to rely on the standard library for this core functionality feels good.
Response time graph showing API p95 latency. Light blue (far left) is the API performance with Zap. Purple (middle) is the performance using log/slog with reflection based redaction using struct tags. The dark blue (far right) is log/slog with a custom LogValuer.
The Arcjet Python SDK allows you to implement rate limiting, bot detection, email validation, and signup spam prevention in FastAPI and Flask style applications.