Kafka is a powerful message queue & streaming platform, but we opted for starting with a much simpler solution: Redis Streams. This is how we use Redis Streams as a queue.
Kafka is a powerful distributed streaming platform, that’s been battle-tested by most large companies and trusted to handle large volumes of data in real time. At first glance, it was obvious that it was perfect for us to use in building Arcjet - a security platform for developers that’s meant to handle requests with as low latency as possible.
However, Kafka is also famously difficult to host and manage, which as a startup isn’t desirable. We can of course outsource this to a managed Kafka provider, but this comes at a very high cost, which is also not ideal for a new startup.
So, what are the alternatives? For us, the choice was clear. We already use Redis as our cache layer and Redis has a Redis Streams offering, so we decided to give it a go and determine whether it could accommodate our needs.
The simplicity of Redis Streams
In theory, Redis Streams is quite straightforward - you read & write messages to the stream with XREAD and XADD respectively.
XADD requestsStream * request "a request"
XREAD COUNT 1 STREAMS requestsStream
XREAD is a blocking command, meaning that it will only return a result once data is available to return. It also allows for specifying how many messages you want to read from the stream, which enables for the user to do batch processing.
When you are done with processing the message you have just read, you can simply delete it using XDEL .
XDEL requestsStream 1538561700640-0
The complexity of Redis Streams
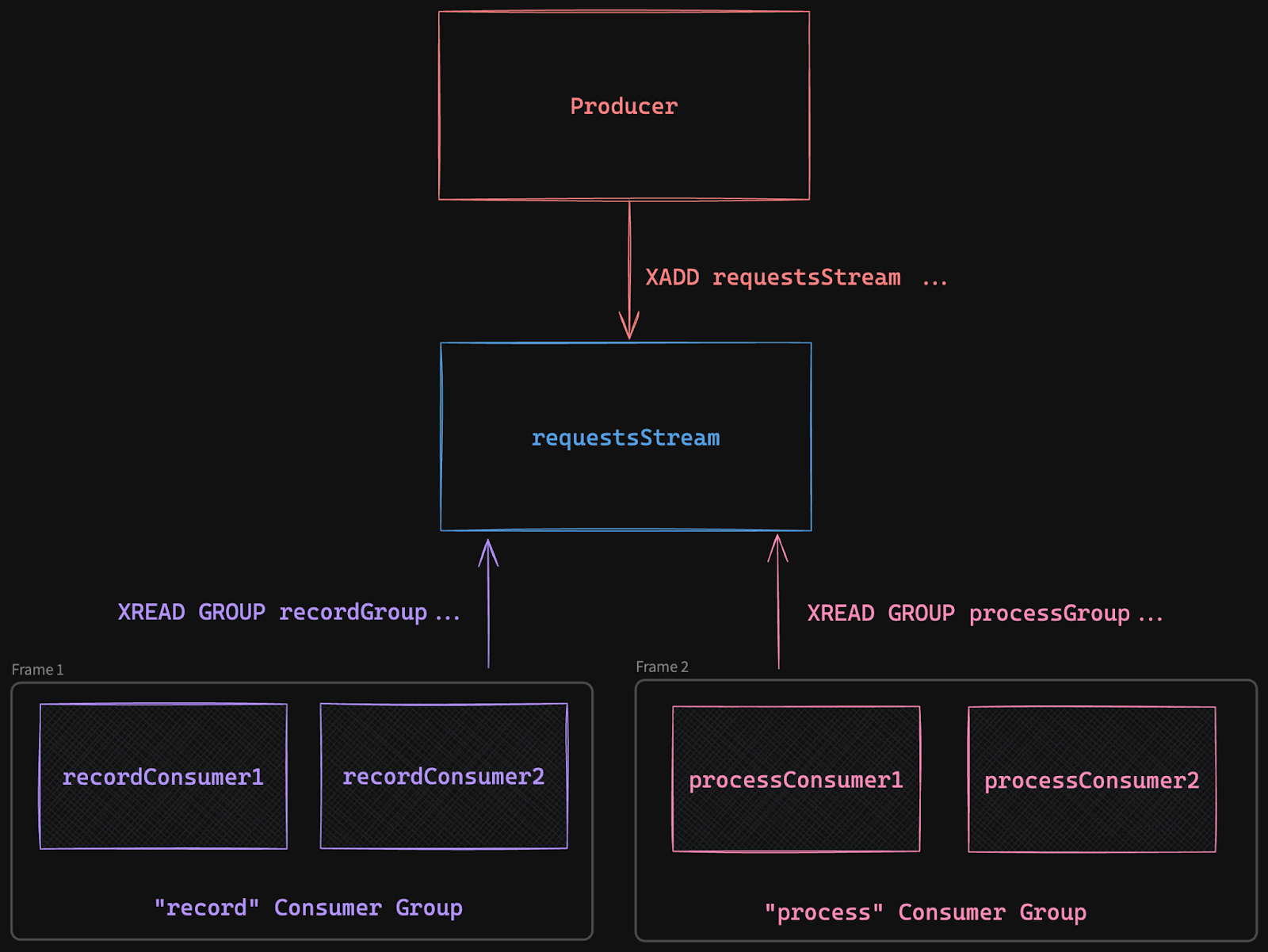
Things get more complicated when you create multiple consumer groups with multiple consumers in each group, all reading from the stream. I will try to illustrate why.
Setting this up is actually simple - you call the XGroupCreate command, provide the stream to read from, give the group a name and configure where it should start reading from:
XGROUP CREATE requestsStream processGroup 0
After the group has been created, you can now use the XREADGROUP command, which works in the same way (in addition to providing the group you want to read from)
XREADGROUP GROUP processGroup processConsumer1 STREAMS requestsStream 0
Here’s where it gets a little bit more complicated.
Where previously we could just delete the message from the stream after we’re done processing it, this is no longer the case with multiple consumer groups because we don’t know whether the other consumer groups have yet processed the message.
For example, if we have one consumer group called “process”, which takes 10 seconds to process a message, and one consumer group “record”, which only takes 1 second to process the same message, the “record” group would go through messages much quicker than the other. If “record” deletes the message after processing, the “process” group would miss messages.
Illustration of multiple consumer groups in a Redis Stream.
You might think “no worries, I will just delete them after processing instead of recording”, but that will not account for other potential problems. Let’s say that your “record” group consumers all crash (worst case scenario) and they fall behind. Deleting as a part of “process” would cause issues again.
So what does Redis provide to handle this? Surprisingly, nothing. On your first search you will find the XACK command and think that’s exactly what you need:
XACK requestsStream processGroup 1526569495631-0
However, acknowledging a message in Redis Streams has a strange behavior. Let’s explore that.
When a message has been read from the stream, it’s added to a pending list. Consumers pull messages from the pending list first to try to process them. This allows consumers joining or re-joining the groups to pick up where they left off. When you acknowledge a message, you guarantee that it won’t be delivered again to consumers of the same consumer group. This is something you want to do when you have multiple consumers in the same group because it helps horizontally scale your applications.
This behavior allows for the implementation of three different delivery strategies - at most once, at least once and exactly once. Each of those strategies come with their pros and cons, so I recommend reading up on it in order to be able to decide on which one suits your needs best.
But what happens to messages once they have been processed and acknowledged by all consumer groups? They get deleted, right? Wrong. Those messages stay in the queue until specifically deleted. They will fill up the Redis instance eventually if nothing else is done about them.
Managing your stream
The real drawback of Redis Streams is that because it’s so simple, it doesn’t really do any hand-holding like you might expect from a dedicated queue such as Kafka. You have to implement the strategy that’s appropriate for your use case when it comes to managing the state of your stream. In this next section, I will show you how we approached the problem of an ever growing queue of messages.
Redis Streams provides you with two ways to ensure the length of your stream/queue doesn’t exceed the limits of your resources (probably memory).
One of them is to specify a MAXLEN limit on adding to the stream:
XADD requestsStream MAXLEN ~ 1000 * ...
Or you can use XTRIM. This will trim the stream by deleting messages from the beginning of the stream by either providing the desired trim length or the minimum ID of a message to delete up to.
XTRIM requestsStream MAXLEN 1000
XTRIM requestsStream MINID 1526569495631-0
The dangerous part of this operation is that when you trim a stream, all messages that fall under that range will be deleted, whether they were processed, acknowledged, read or not. If you don’t care about data loss, then you are in luck - schedule a job that executes the command and you’re done. I have a feeling however that most developers wouldn’t want to risk deleting messages that might not have been processed, so here’s our approach.
We have created a process called “Janitor” which is responsible for giving us insights on the stream length, consumer groups and other useful details. Logging and metrics in our other processes helps to figure out what our processing speed is, e.g. 100 messages per minute. Knowing this number lets us periodically trim the stream via Janitor to delete the number of messages we have processed since the last time we’ve invoked Janitor.
But it’s worth pointing out that this isn’t an exact science - our codebase is always evolving and processing times are variable, particularly as the volume of traffic we’re receiving changes. This means we can still fall behind with cleaning up. This is why we have set up alerts that would notify us well in advance if our stream length is getting out of hand, at which point we can act accordingly by either spinning up more consumers or trimming the stream further.
This is however not our permanent plan for managing the stream. Since we’re already using Redis, we can utilise it to persist the state of processing i.e. saving which IDs have been processed by all consumer groups. This is a work in progress, so stay tuned for part two!
Conclusion
In the end Redis Streams met our requirements for scalability, ease of management and low cost. We can use a generic Redis cluster for much lower cost than managed Kafka services (on the order of ($1k/yr vs 6 figure licensing fees for commercial Kafka services). See our evaluation of AWS ElastiCache serverless.
We spent some time writing our own management tools - something you always need to do with core infrastructure anyway - and kept the setup very simple. We’ll see how this scales, but our requirements for a queue are simple enough that it seems like Redis will continue to work well for us for a while.
Further tips and reading
Redis Insight was crucial for our development and helped us debug exactly what was happening with the stream so I highly recommend using it. It helps you visualise your data while it’s being processed.
Redis’ own Streams page does a really good job describing the fundamentals of Redis Streams, so I would definitely advise you to read through it, should you decided it’s something you want to integrate within your open system.
The Arcjet Python SDK allows you to implement rate limiting, bot detection, email validation, and signup spam prevention in FastAPI and Flask style applications.