Reviewing Arcjet's usage of AWS ElastiCache Serverless Redis. Great if you don’t want to think about clusters, nodes and shards, but the pricing is difficult to calculate.
Redis is a crucial component of the Arcjet infrastructure. We use it as both a queueing system and a fast in-memory datastore for tracking rate limits. By installing the Arcjet developer SDK you get access to various security primitives, such as rate limiting, without needing to think about managing the infrastructure to support them. But behind the scenes we’re using Redis.
We deploy everything to AWS and prefer managed services over running things ourselves. We really only want to run the code we write. This post is about our usage of AWS’s managed Redis service: ElastiCache.
Using Redis for in-memory storage
The Arcjet API is used by the SDK when a decision cannot be taken locally within the developer’s environment. This most often happens when a rate limit rule is configured and we need to track clients across requests. In serverless functions, the environment is recycled after every request (or after a short period of time) so tracking rate limits in-memory is unfeasible.
This is often solved by using Redis, but then the developer is responsible for maintaining & scaling the Redis cluster. Performance becomes a challenge when this needs to be distributed across multiple data centers.
Our API is deployed in at least 2 zones within each AWS region. We load balance across the zones to provide resilience to regional failure. We also want to be close to the developer’s application to achieve our low-latency goals, so we deploy to multiple regions.
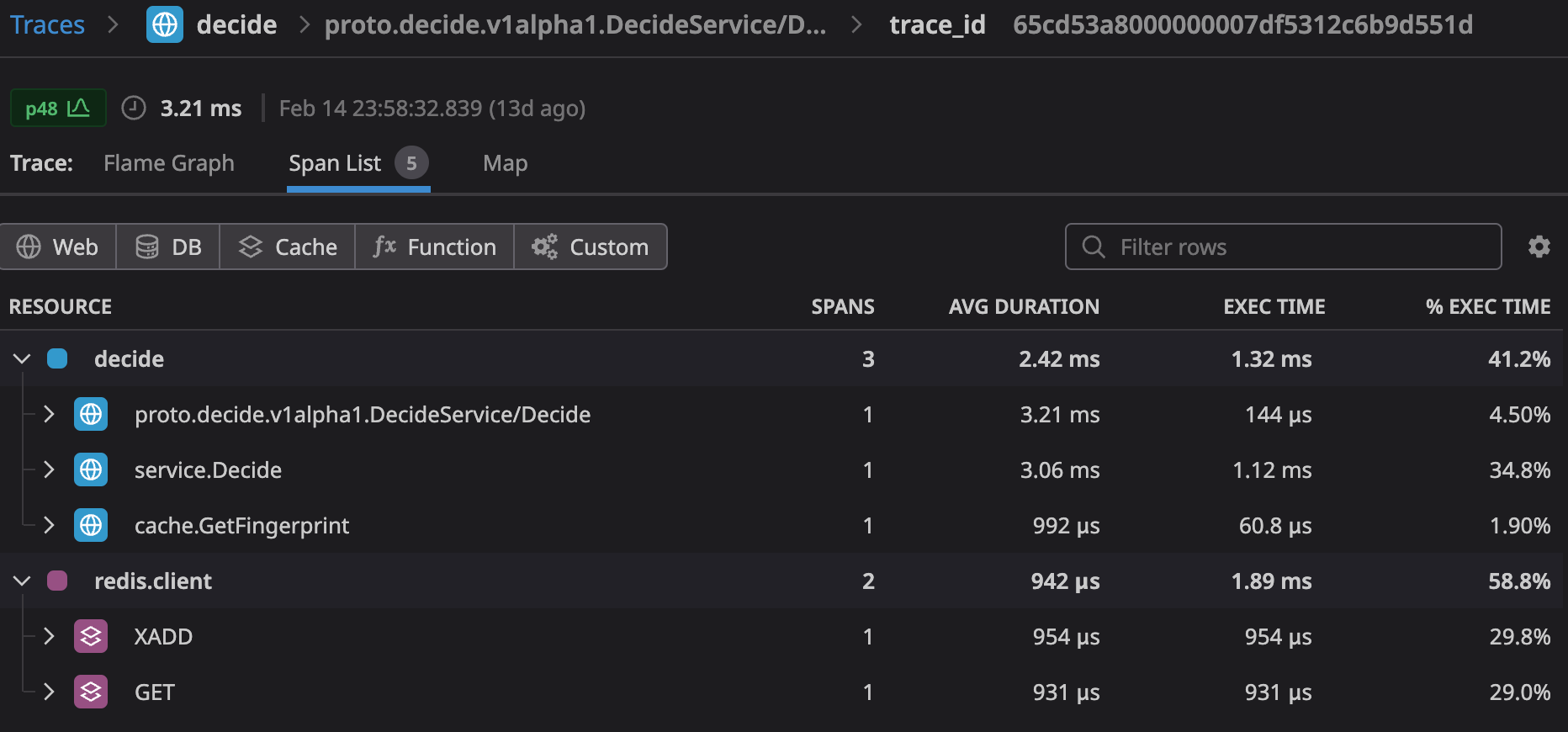
We also want our Redis clusters to be as close as possible to our code to minimize any latency between the container and Redis. AWS zones are effectively individual data centers far enough from each other to avoid localized outages taking down the whole region, but close enough for single digit millisecond latency between them. However, that is too slow for our performance goals so this means deploying Redis within the same zone as the containers. Redis is very fast because it’s optimized for in-memory usage, so we don’t want to ruin that performance by adding lots of network hops.
Mostly sub-millisecond performance with ElastiCache.
Starting with ElastiCache nodes
I started building out the Arcjet infrastructure in the summer of 2023 before the serverless option existed. I picked the entry-level cache.t4g.micro nodes which are the cheapest and offer 2 vCPUs and 0.5GB of memory.
Redis operates with the concept of a single primary node and multiple replicas. In Redis cluster mode the client is aware of which shard a particular key lives in. All writes go to the single primary node, but you can read from any node.
For our latency goals we want all nodes, or at least the primary, to be in the same zone as the client performing the write. AWS allows you to deploy within a single zone, but not if you want automatic node failover. This is important for handling failures, so I chose to deploy across multiple availability zones and enabled cluster mode so we would have the option to choose to scale by adding nodes or by increasing the node size (or both).
This proved difficult because AWS doesn’t tell you which node is currently the primary - you have to query it directly from Redis. AWS allows you to trigger a failover, but the idea is that you don’t need to worry about which node is the primary.
For most applications this wouldn’t be a problem - you delegate the responsibility for managing the cluster to AWS and the latency across zones is low. We see low single digit milliseconds total response time when making calls to ElastiCache Redis across zones. However, this isn’t low enough when compared to the sub millisecond response times if the primary is within the same zone.
A further complication arises when using Terraform. Using the automatic failover option requires a multi-AZ deployment, but the Terraform module doesn’t support specifying the preferred availability zones. This is being tracked by hashicorp/terraform-provider-aws#5188. So if we deploy to a single zone then we lose auto-failover, but if we deploy with multi-AZ then we can’t decide which zone the primary node is deployed to.
Aside from these quirks and the very slow deployment times (it takes 20-30 minutes to deploy a new instance), we’ve had no issues with ElastiCache. It works as advertised, is reliable, and allowed us to hit our performance goals when the primary was in the correct zone.
Experimenting with ElastiCache serverless
ElastiCache serverless was introduced in Nov 2023 so when we were getting ready for our first SDK release in Dec 2023 I decided to try it out. Aside from provisioning within a minute, the main benefit is classic serverless marketing:
ElastiCache Serverless constantly monitors your application’s memory, CPU, and network resource utilization and scales instantly to accommodate changes to the access patterns of workloads it serves…ElastiCache Serverless offers a simple endpoint experience abstracting the underlying cluster topology and cache infrastructure. You can reduce application complexity and have more operational excellence without handling reconnects and rediscovering nodes.
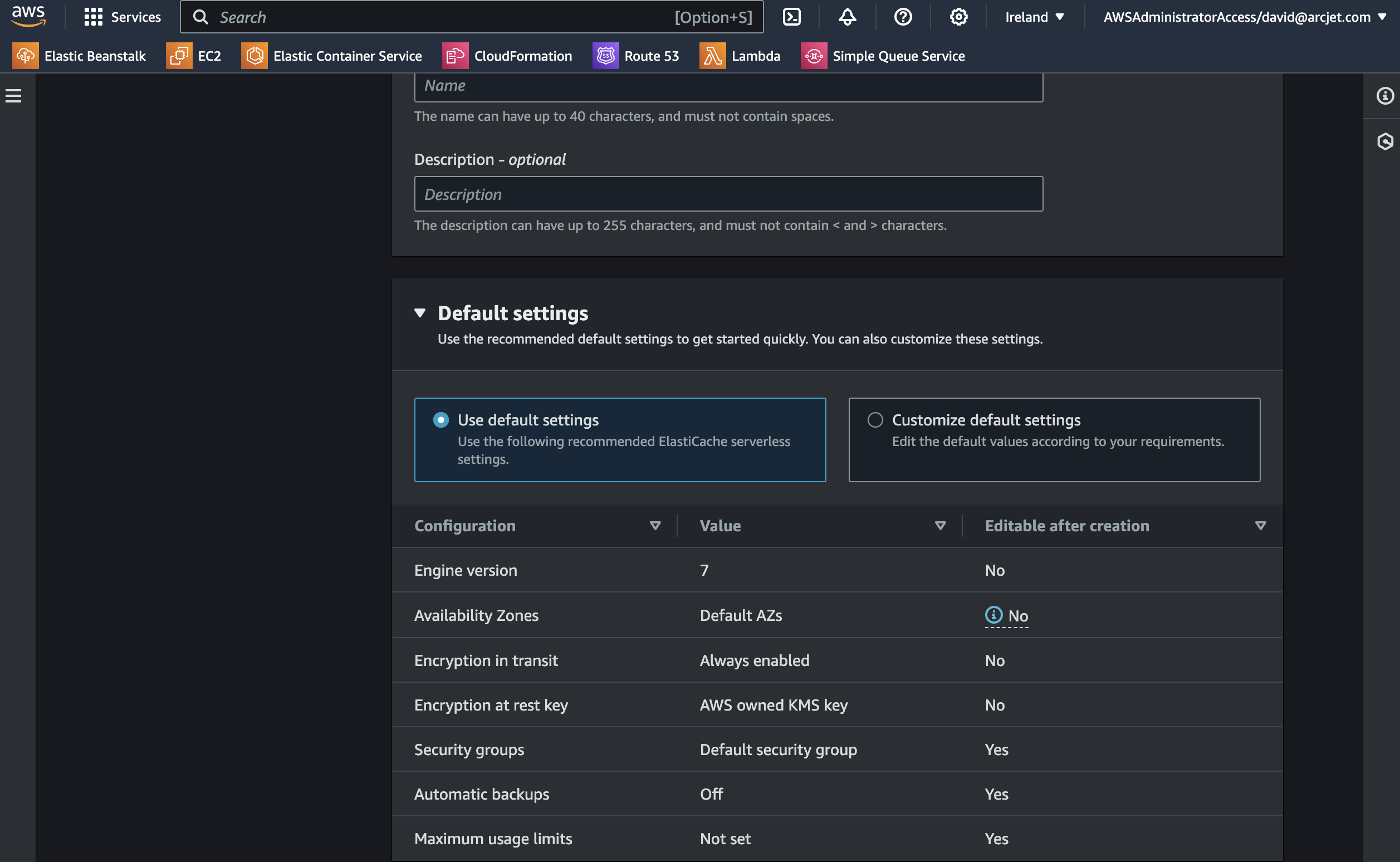
This actually delivers on the promise! As with ElastiCache Redis with cluster mode enabled, you get a single endpoint to point your client at. However, with a serverless instance there is no concept of primaries, nodes or shards. When deploying the cluster you choose which zones you want it to be available in and that’s it. Node placement is handled by AWS so all you need to do is send commands.
In our testing we get sub-millisecond response times for both reads and writes regardless of which zone the client is in. How this works behind the scenes is unclear / undocumented because we have seen an occasional primary failover. Our queue consumers are constantly watching for new messages and we’ve seen multiple Redis state changes with the error:
UNBLOCKED force unblock from blocking operation, instance state changed (master -> replica?)
This indicates that perhaps AWS is sharding by zone so writes are always local, with data being replicated automatically across the specified zones. Even so, we’re seeing very good performance and having a single endpoint regardless of the zone has made it much easier for us to manage than multiple instances where we’re unsure which node is primary at any given time.
Options when creating an ElastiCache serverless instance.
Complex serverless pricing
The main downside I see with ElastiCache serverless is that the pricing makes it difficult to predict the overall cost. When you deploy a standard cluster you pick the node size and each node has a fixed price per hour. The obvious downside to this is that it doesn’t auto-scale with usage. But maybe most people don’t need that.
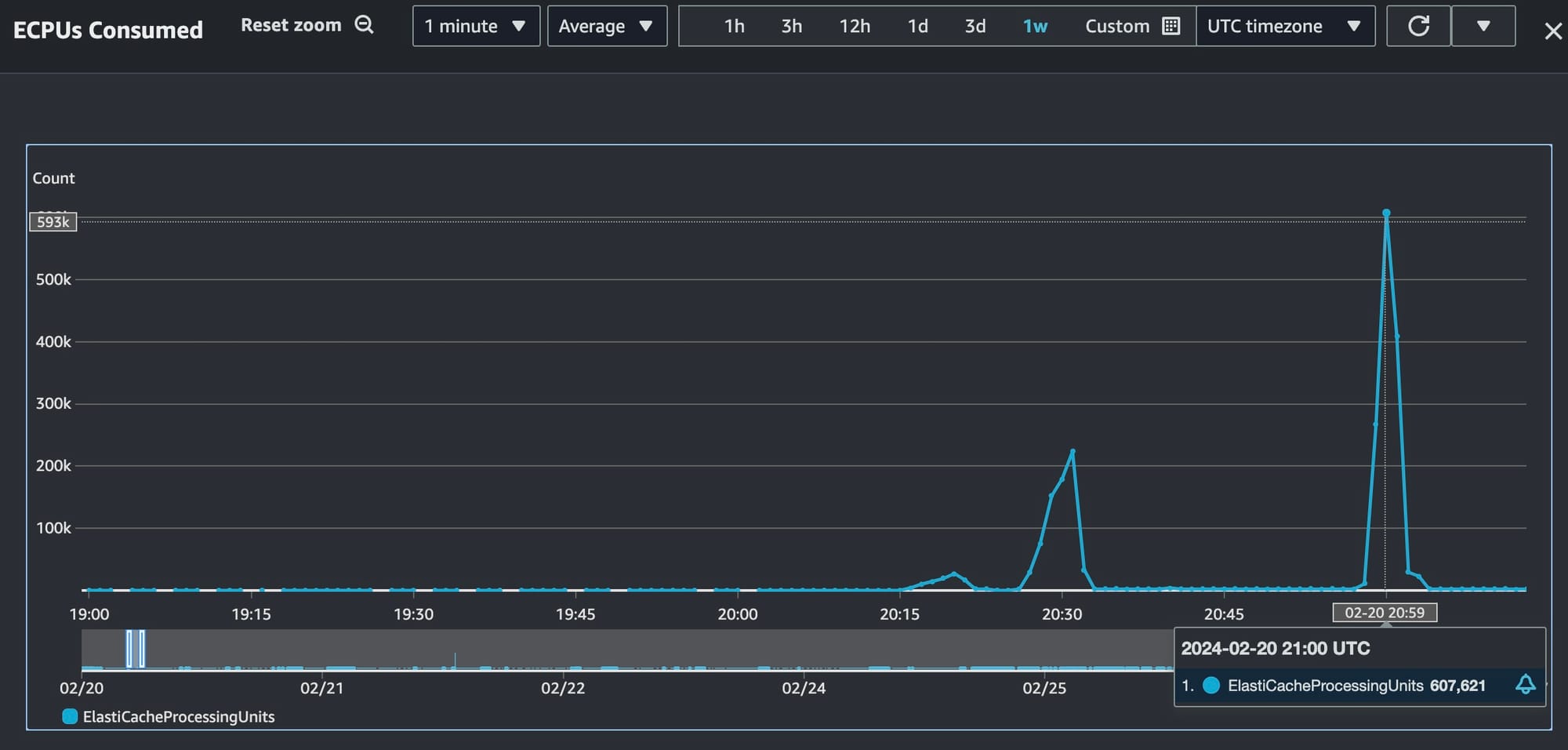
ElastiCache serverless pricing is based on a combination of storage billed in gigabyte-hours and ElastiCache Processing Units (ECPUs). It’s this ECPU unit that makes things difficult because it “includes both vCPU time and data transferred. Reads and writes require 1 ECPU for each kilobyte (KB) of data transferred.” AWS uses the example “a GET command that transfers 3.2 KB of data will consume 3.2 ECPUs”.
I would bet that most people don’t know how much vCPU time or data is consumed as part of their normal usage of Redis. Are your cache items always a fixed size? It’s hard to predict, especially as the application evolves.
ElastiCache serverless is also not truly serverless because it doesn’t scale to $0 at zero usage. There is a minimum billing amount of 1GB which at $0.125 / GB-hour means a minimum cost of $3 per day (in us-east-1).
ElastiCache serverless ECPU consumption during a load test going from 0 req/s to 500 req/sec over 5 min.
Conclusion
We’ve switched all our ElastiCache Redis clusters to using a single serverless instance in each region. This has significantly simplified our setup because we no longer need to think about which node is primary in which zone. As we spin up new regions we can estimate the baseline cost and then Redis automatically scales as traffic ramps up.
Our plan is to monitor the cost of each serverless cluster in each region. As our traffic grows we’ll regularly re-evaluate whether it still makes sense to continue with a serverless instance or to switch to fixed capacity nodes. This will become more important at scale not just because of the higher capacity those fixed nodes offer for a better price, but also because you can buy reservations to lock in much lower prices. Reserved pricing is not available for serverless.
So my conclusion is that ElastiCache serverless Redis is great if you just want to get started and/or don’t want to think about clusters and nodes and shards. It’s also great if you have no idea what your traffic is going to be and have unpredictable scaling needs.
For other use cases, it may be a good place to start if you don’t mind the $3/day cost vs $0.38 per day for the smallest fixed node instance ($1.14 if you have x3 nodes in a redundant cluster, which is what serverless is actually doing for you). But this is probably overkill for most simple caching workloads where a single node is likely to do what you need.
The Arcjet Python SDK allows you to implement rate limiting, bot detection, email validation, and signup spam prevention in FastAPI and Flask style applications.