The Silk Road, a “darknet” black market, was the platform of choice for drug dealers and vendors of illegal goods and services from 2011 to 2013. During its time online, massive quantities of illicit goods were distributed, various illegal services were advertised and all the proceeds were laundered.
In September of 2012, James Zhong, created several accounts on Silk Road in an attempt to further obfuscate his identity, as he was about to steal from the coffers of the black market. By exploiting a race condition vulnerability in the platform’s withdrawal-processing system, he was able to duplicate the same withdrawal transactions. With an initial investment between 200 and 2,000 Bitcoin, over the course of 140 transactions in rapid succession, Zhong was able to extract approximately 50,000 Bitcoin.
At the time of the heist, the crypto-currency was trading below $13. Zhong had successfully stolen ~$650,000 from the Silk Road. Nine years later, on November 9th of 2021, U.S. federal authorities raided Zhong’s house in Georgia and discovered an underground safe that contained a single-board computer. This single circuit board held the wallet with the ill-gotten gains, which at the time of seizure, had ballooned into $3.3 billion.
What is a Race Condition Vulnerability?
A race condition vulnerability occurs when a system that is designed to handle tasks sequentially, mistakenly allows two or more tasks to operate on the same data simultaneously. If multiple tasks interact with the same data at the same time, a “collision” occurs. The time period in which these collisions can occur is called a “race window”. These race windows can be extremely brief, often lasting just milliseconds or less.
If the intended outcome of a process relies on the correct timing or order of task execution, an exploited race condition vulnerability can lead to unintended consequences.
What is a Race Condition Attack?
An attack against a race condition vulnerability is carried out by intentionally causing collisions to bypass control mechanisms. Any application that relies on control mechanisms to perform sensitive actions could be vulnerable to this type of attack.
Limit Overrun Attack
In a limit overrun attack, an imposed application limit is bypassed or exceeded.
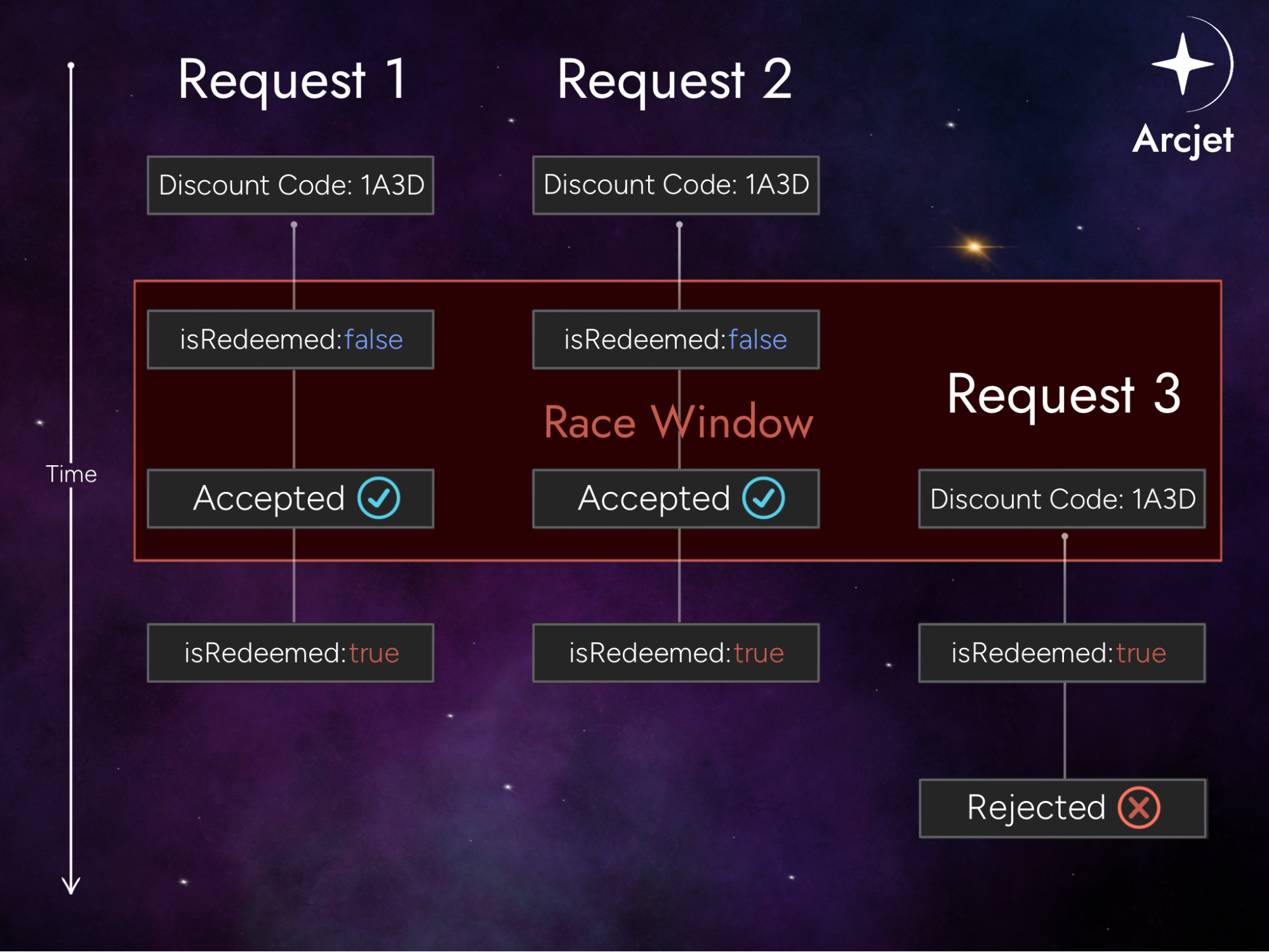
To illustrate, imagine an online retailer is offering a one-time-use discount code for purchases. The intended flow is as follows:
A user submits the discount code.
The server queries the database to verify the user has not yet redeemed the code yet.
If the code is valid, the discount is applied, and the database is updated to mark the code as redeemed.
If the user tries to use the code again, the system prevents it at step 2 by detecting that the code has already been redeemed.
However, if multiple requests to redeem the code are submitted simultaneously, the server might process more than one request before the database is updated. This could allow the same discount code to be applied multiple times.
In the scenario above, the first two requests arrived within a brief window (a race condition), before the database had updated the code’s status to “redeemed.” Since the isRedeemed flag was not yet set to true, both requests were processed as valid, and the discount was applied twice.
The third request, which arrived later, was rejected because the database had already marked the code as redeemed.
Single-endpoint Attack
Many endpoints operate on specific objects using a unique identifier, such as a username. If an attacker can cause a key collision, submitting two different values could result in data corruption. Exploiting this behavior is known as a single-endpoint attack.
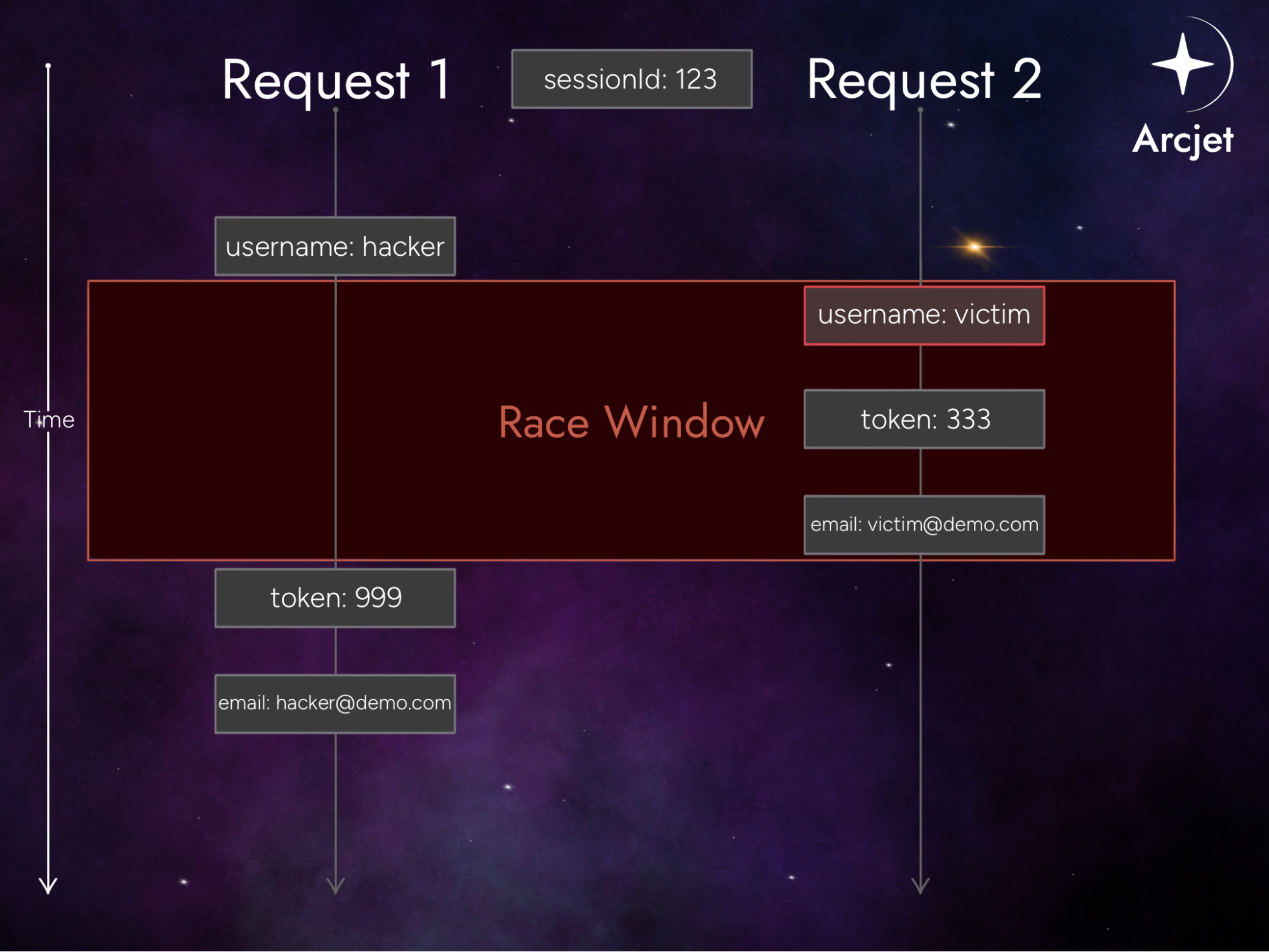
Imagine a web application that offers password reset functionality with the following user database structure:
Once a user is authenticated and receives a session token, they can reset their password by submitting their username.
The server generates a unique password reset token linked to both the session token and the provided username. The reset token is stored in a database with the structure shown above.
This reset token is emailed to the user.
User submits a new password with the token.
When the server receives this request, it verifies that the token matches the one stored in the database, ensuring that both the session and username are valid.
However, if multiple password reset requests are submitted simultaneously within the same session but with different usernames, a key collision may occur.
In the scenario above, both task threads will attempt to alter the same sessionId’s token and username attributes. With a little luck, the threads could overwrite each other in such a way that the token becomes associated with the victim’s username, but the token is sent to the attacker’s email. This results in the attacker gaining control of the password reset process.
Multi-endpoint Attack
In some processes, multiple endpoints share data concurrently, particularly when a single request triggers a chain of background operations. Once all these operations are completed, the system returns the final response.
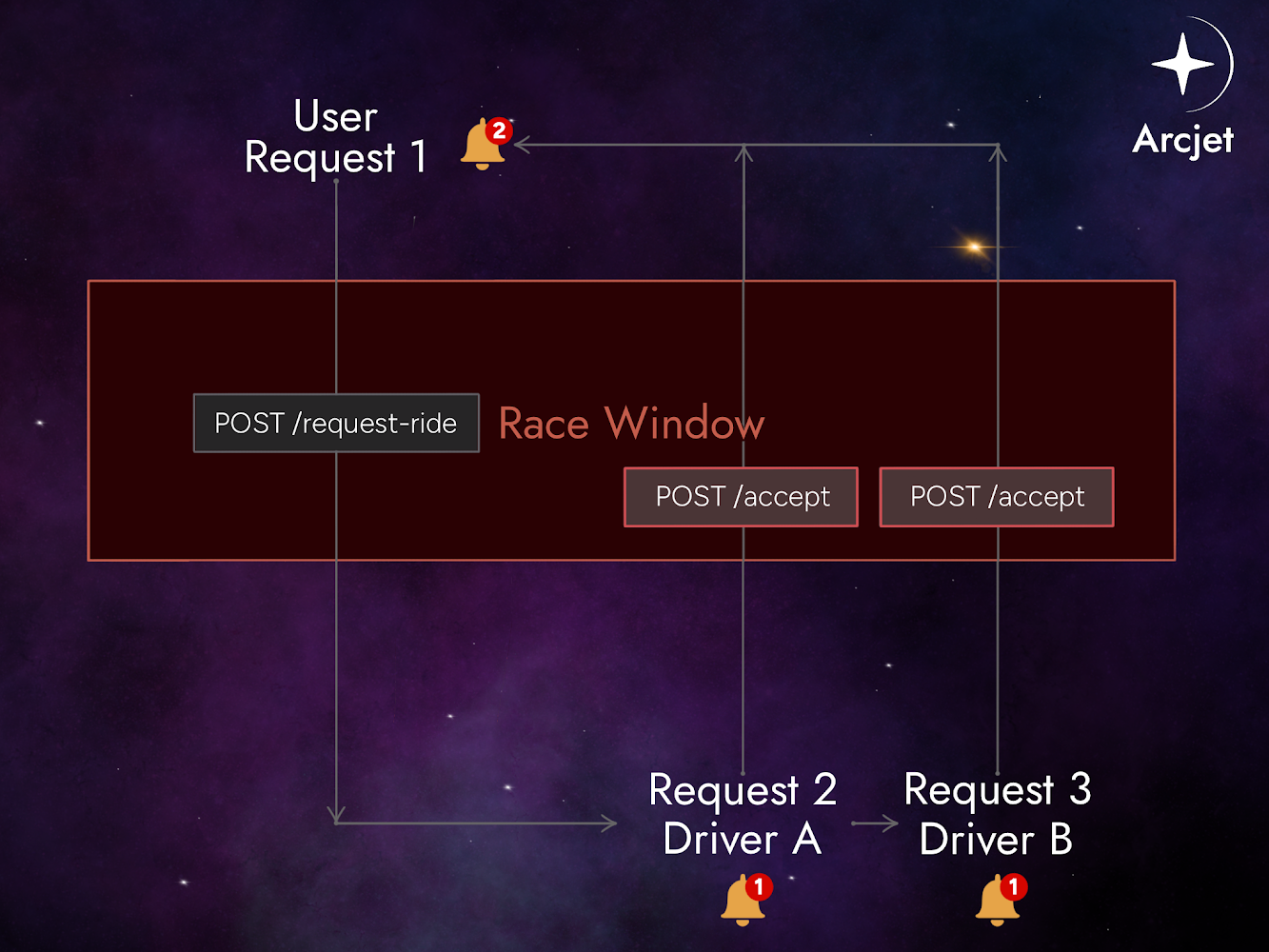
Consider a ride sharing application that enables users to request a ride and drivers can accept those requests.
The system has two endpoints:
Endpoint A: /request
Endpoint B: /accept
The intended flow is as follows:
The user requests a ride by calling the /request endpoint.
The request is processed and sends notifications to every available driver.
Once a driver accepts the request, the user and driver are paired.
If the system does not handle the ride request’s state properly, multiple drivers could be assigned to the same ride. This can happen if their acceptance requests are processed within the same time frame.
In the image above, two drivers accepted the same ride request. Since both requests were processed within the race window, the user is now assigned two different drivers.
Preventing Race Condition Vulnerabilities: A Checklist for Developers
To mitigate your risk level to race condition attacks, there are several steps you can take to review and secure your environment.
Code Review and Analysis
When evaluating your code base for race condition vulnerabilities, focus on areas that access the same resources. Static analysis tools such as SonarQube and Coverity can identify potential issues with concurrency and synchronization before the code is deployed. Dynamic analysis tools can be used to monitor the application during runtime for clues of a race condition such as data corruption or state change inconsistencies.
Implement Thread Synchronization Techniques
Multiple synchronization techniques can be implemented in your code in order to avoid collisions:
Mutexes
A mutex (mutual exclusion) ensures only one thread can access a resource at a time. When a thread locks a mutex, other threads trying to lock it will be blocked until it is unlocked. This prevents multiple threads from modifying shared resources simultaneously.
class Mutex {
private isLocked = false;
private waiting: (() => void)[] = [];
async lock(): Promise<void> {
while (this.isLocked) {
await new Promise<void>(resolve => this.waiting.push(resolve));
}
this.isLocked = true;
}
unlock(): void {
if (!this.isLocked) {
throw new Error('Mutex is not locked');
}
this.isLocked = false;
if (this.waiting.length > 0) {
const next = this.waiting.shift();
if (next) next();
}
}
}
const mutex = new Mutex();
let sharedCounter = 0;
async function increment() {
for (let i = 0; i < 100000; i++) {
await mutex.lock();
sharedCounter++;
mutex.unlock();
}
}
(async () => {
const promises = [increment(), increment()];
await Promise.all(promises);
console.log(`Final counter value: ${sharedCounter}`);
})();
TypeScript mutex example.
import threading
shared_counter = 0
mutex = threading.Lock()
def increment():
global shared_counter
for _ in range(100000):
mutex.acquire()
shared_counter += 1
mutex.release()
threads = []
for _ in range(2):
thread = threading.Thread(target=increment)
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
print(f'Final counter value: {shared_counter}')
Python mutex example.
package main
import (
"fmt"
"sync"
)
var (
wg sync.WaitGroup
mutex sync.Mutex
sharedCounter int
)
func increment() {
for i := 0; i < 100000; i++ {
mutex.Lock()
sharedCounter++
mutex.Unlock()
}
wg.Done()
}
func main() {
wg.Add(2)
go increment()
go increment()
wg.Wait()
fmt.Printf("Final counter value: %d\n", sharedCounter)
}
Go mutex example.
Semaphores
A semaphore is a signaling mechanism that controls access to a shared resource through a counter. There are two types of semaphores: binary and counting. Binary semaphores, similar to a mutex, only allow one thread to access a certain resource at a time. A counting semaphore allows a specified number of threads to access a resource simultaneously, based on a counter that will increase when a thread acquires the semaphore and will decrease when a thread releases it.
class Semaphore {
private tokens: number;
private waiting: (() => void)[] = [];
constructor(tokens: number) {
this.tokens = tokens;
}
async acquire(): Promise<void> {
if (this.tokens > 0) {
this.tokens--;
} else {
await new Promise<void>(resolve => this.waiting.push(resolve));
}
}
release(): void {
this.tokens++;
if (this.waiting.length > 0) {
const next = this.waiting.shift();
if (next) next();
}
}
}
const semaphore = new Semaphore(2);
let sharedCounter = 0;
async function accessResource(id: number): Promise<void> {
console.log(`Thread ${id} is waiting to access the resource.`);
await semaphore.acquire();
console.log(`Thread ${id} has accessed the resource.`);
await new Promise(res => setTimeout(res, 1000));
console.log(`Thread ${id} is releasing the resource.`);
semaphore.release();
}
(async () => {
const promises: Promise<void>[] = [];
for (let i = 0; i < 5; i++) {
promises.push(accessResource(i));
}
await Promise.all(promises);
})();
TypeScript semaphore example.
import threading
import time
semaphore = threading.Semaphore(2)
def access_resource(thread_id):
print(f'Thread {thread_id} is waiting to access the resource.')
semaphore.acquire()
print(f'Thread {thread_id} has accessed the resource.')
time.sleep(1)
print(f'Thread {thread_id} is releasing the resource.')
semaphore.release()
threads = []
for i in range(5):
thread = threading.Thread(target=access_resource, args=(i,))
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
Python semaphore example.
package main
import (
"fmt"
"sync"
"time"
)
var wg sync.WaitGroup
func accessResource(id int, semaphore chan struct{}) {
fmt.Printf("Thread %d is waiting to access the resource.\n", id)
semaphore <- struct{}{}
fmt.Printf("Thread %d has accessed the resource.\n", id)
time.Sleep(1 * time.Second)
fmt.Printf("Thread %d is releasing the resource.\n", id)
<-semaphore
wg.Done()
}
func main() {
semaphore := make(chan struct{}, 2)
for i := 0; i < 5; i++ {
wg.Add(1)
go accessResource(i, semaphore)
}
wg.Wait()
}
Go semaphore example.
Monitors
A monitor is a synchronization mechanism that combines mutexes and conditional variables. Only one thread is allowed to execute a section of code at a time, ensuring mutual exclusion. By requiring certain conditions to be met, it provides a way for threads to wait their turn in the process, only to be called upon when the data is ready to work with.
import threading
condition = threading.Condition()
shared_resource = 0
def producer():
global shared_resource
with condition:
shared_resource += 1
print('Produced:', shared_resource)
condition.notify()
def consumer():
global shared_resource
with condition:
while shared_resource == 0:
condition.wait()
print('Consumed:', shared_resource)
shared_resource -= 1
threads = []
for _ in range(2):
threads.append(threading.Thread(target=producer))
threads.append(threading.Thread(target=consumer))
for thread in threads:
thread.start()
for thread in threads:
thread.join()
Python monitor example.
package main
import (
"fmt"
"sync"
)
type Monitor struct {
mu sync.Mutex
cond *sync.Cond
resource int
}
func NewMonitor() *Monitor {
m := &Monitor{}
m.cond = sync.NewCond(&m.mu)
return m
}
func (m *Monitor) Produce() {
m.mu.Lock()
m.resource++
fmt.Println("Produced:", m.resource)
m.cond.Signal()
m.mu.Unlock()
}
func (m *Monitor) Consume() {
m.mu.Lock()
for m.resource == 0 {
m.cond.Wait()
}
fmt.Println("Consumed:", m.resource)
m.resource--
m.mu.Unlock()
}
func main() {
monitor := NewMonitor()
var wg sync.WaitGroup
for i := 0; i < 2; i++ {
wg.Add(1)
go func() {
defer wg.Done()
monitor.Produce()
}()
wg.Add(1)
go func() {
defer wg.Done()
monitor.Consume()
}()
}
wg.Wait()
}
Go monitor example.
Atomic operations
Atomic operations allow threads to safely modify shared variables without requiring locks. They are typically used for simple task schedules to complete them in a single step relative to other threads. This means once an atomic operation begins, it cannot be interrupted by other threads.
const buffer = new SharedArrayBuffer(4);
const sharedCounter = new Int32Array(buffer);
async function increment() {
for (let i = 0; i < 100000; i++) {
Atomics.add(sharedCounter, 0, 1);
}
}
(async () => {
const promises = [increment(), increment()];
await Promise.all(promises);
console.log(`Final counter value: ${sharedCounter[0]}`);
})();
TypeScript atomic example.
import threading
import time
shared_counter = 0
def increment():
global shared_counter
for _ in range(100000):
temp = shared_counter
time.sleep(0)
shared_counter = temp + 1
threads = []
for _ in range(2):
thread = threading.Thread(target=increment)
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
print(f'Final counter value: {shared_counter}')
Python atomic example.
package main
import (
"fmt"
"sync"
"sync/atomic"
)
var sharedCounter int32
func increment(wg *sync.WaitGroup) {
for i := 0; i < 100000; i++ {
atomic.AddInt32(&sharedCounter, 1)
}
wg.Done()
}
func main() {
var wg sync.WaitGroup
wg.Add(2)
go increment(&wg)
go increment(&wg)
wg.Wait()
fmt.Printf("Final counter value: %d\n", sharedCounter)
}
Go atomic example.
Most programming languages have locking functionality. For example, Python’s threading.Lock, Go’s sync.Mutex or Java’s synchronized keyword. Even if a language lacks built-in locking, many third-party modules or libraries are available. Search for lock documentation in any code you use that uses multithreading.
Be aware that while these techniques will reduce the risk of a race condition vulnerability being present in your code base, by removing concurrency, the application can become slower as additional threads must wait until they are allowed access.
What is known as a “deadlock” can also occur when two threads each lock a different variable at the same time and then try to lock each other's variables. When this happens, both threads will stop executing and will wait an indefinite amount of time for the other to release their lock.
Conclusion
By being aware of how race condition vulnerabilities arise and how they are exploited, you can better protect your applications against them. While multithreading and asynchronous programming increase the speed of your application, as with all development techniques there are associated risks.
Educating your teams on the dangers of concurrent programming will produce a community of security conscious developers–ensuring the safety of your organization and users.
Discover the hidden risks of using trivial packages in development. Learn how small, seemingly insignificant dependencies can lead to significant security vulnerabilities.
Discover essential strategies for managing developer secrets and preventing leaks in CI/CD pipelines, version control systems, and third-party dependencies.