The hard part isn’t “blocking bots.” It’s correctly distinguishing malicious scrapers from legitimate AI agents so you don’t break useful features (search, citations, assistants) while still stopping abuse.
Today there’s a new player - the AI agent. ChatGPT’s agent mode (released July 2025) shows what a browser-capable agent can actually do.
As a site owner, you now have to choose what automated traffic to allow and where: Should your content power AI answers? Should agents be allowed to sign up and act on behalf of users? Do you even want to block Google?
I’ve discussed these questions and the various techniques for bot detection in a previous post. But what happens next? You’ve decided what traffic you want, but how do you verify that a request is coming from who it claims to be? That’s what this post is about - how to verify and distinguish between malicious bots and AI agents.
User agent
The user agent string is the easiest way to identify a bot - or at least who the bot claims to be. Provided as an arbitrary string value, it’s supposed to be included in the HTTP headers for every request, but that also means it's trivial to spoof.
You can see this in action by using curl to make a request from your terminal. The request header User-Agent: curl/8.7.1 is included by default:
Open your web browser devtools and you’ll be able to see the same thing from the Network tab, but it will be the user agent of the browser you’re using e.g. Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36
You’ll see strings like OAI-SearchBot/1.0; +https://openai.com/searchbot for OpenAI’s search indexing bot which is very similar to Google’s Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Googlebot/2.1; +http://www.google.com/bot.html) Chrome/W.X.Y.Z Safari/537.36 user agent.
However, this value can be set to anything which means it’s very easy to fake. Malicious bots will pretend to be legitimate browsers to try and bypass basic user agent checks. You can try this yourself by changing curl’s user agent:
This is how bad bots get around simple protections - they just change their user agent to one used by a legitimate web browser.
That’s where verification comes in.
Bot IP verification
The first step to verifying bot traffic is IP address verification. This simply means checking that the request source IP address belongs to who it claims to be. All the big bot operators provide lists of their IP addresses that you can check, so if a request claims to be from OpenAI you can check that the IP address is actually on the list.
The way this is usually implemented is through reverse DNS lookups. This avoids needing to keep an updated list of IPs to check against. The process is simple:
Check the host of the request IP address is from one of the expected domains.
Run a forward DNS lookup on the domain that is returned and check the IP address matches the original request IP.
Otherwise, we can use the list of published addresses to check that the IP address matches.
package main
import (
"fmt"
"net"
)
func main() {
_, subnet, _ := net.ParseCIDR("20.42.10.176/28")
sourceIp := net.ParseIP("20.42.10.1")
if subnet.Contains(sourceIp) {
fmt.Println("IP in subnet", sourceIp)
} else {
fmt.Println("IP not in subnet")
}
}
IP address verification allows us to trust the user agent string and confirm who the client is. This means you can be sure that Google and OpenAI search indexers can crawl your site whilst blocking any other types of bot.
But what if an AI agent is using a browser? It will look like any other human (or bot) with an automated Chrome instance. This is where agent signatures come in.
AI agent signatures
If you ask ChatGPT to visit a website in agent mode, it launches a web browser and then acts like a human by following your instructions. It’s actually a real browser, so the user agent will appear to be a legitimate Chrome user.
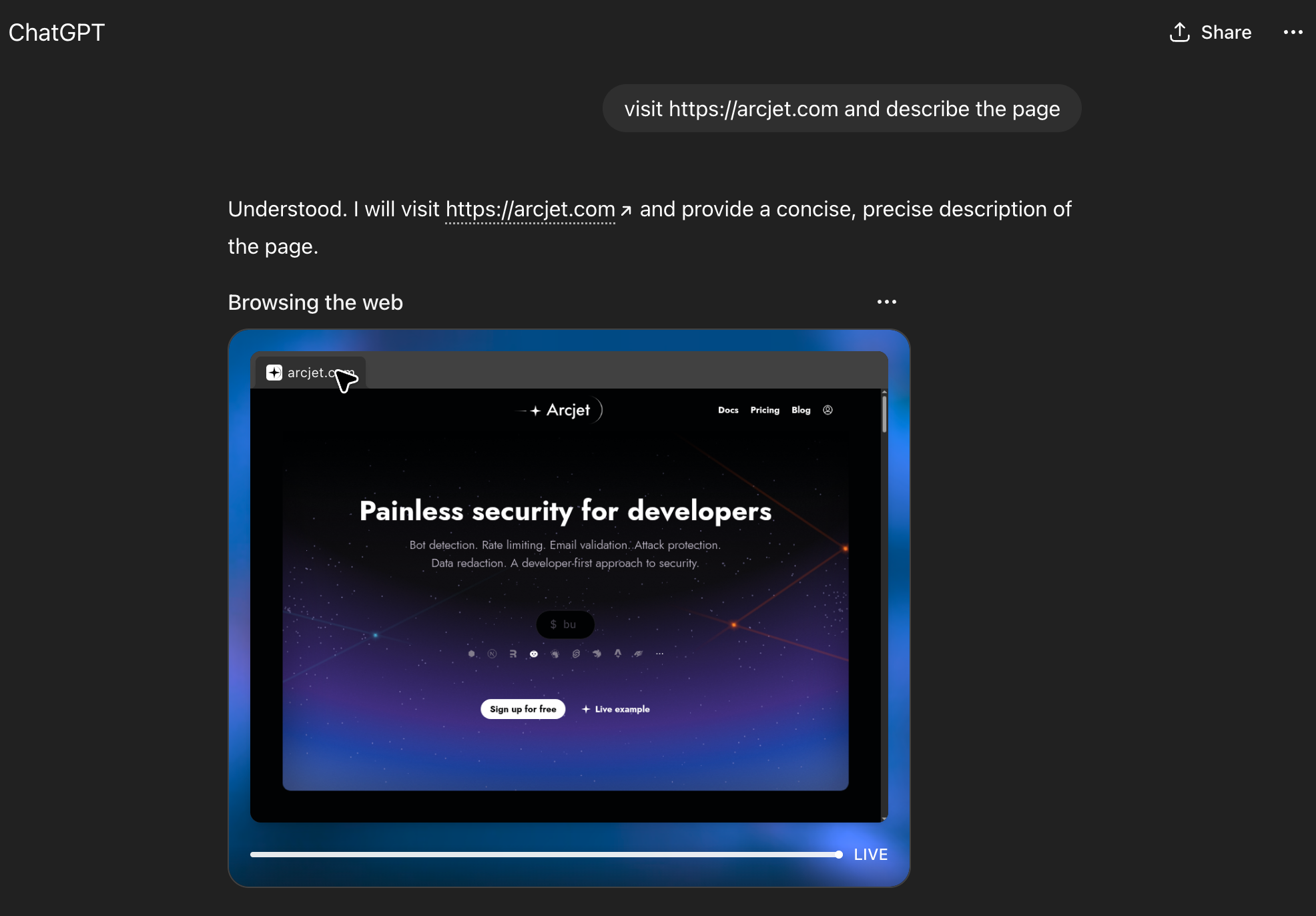
How can we detect these types of AI bots? Let’s look at requests made by OpenAI in agent mode.
ChatGPT browsing arcjet.com in agent mode.
Inspecting the server request logs showed a few interesting things:
The request source IP address was 104.28.192.60 belonging to Cloudflare, not OpenAI.
The IP address geolocates to the UK, which is where I was when I was talking to ChatGPT.
The user agent header was a standard Chrome string: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36
These headers give a confused picture. We can detect Cloudflare’s IP which will be categorized as a “hosting” IP address. These types of IPs tend to be used for abuse because it’s easy to spin up a new VM, container, function, or browser automation. We could just block all hosting IPs, but what if there are legitimate use cases for allowing the use of agents on your website? Maybe you want to allow an agent to browse your documentation, but don’t want to allow them to sign up.
ChatGPT Agent signs every outbound HTTP request using RFC 9421 HTTP Message Signatures, plus a Signature-Agent header set to "https://chatgpt.com" (including the quotes).
As defined by the spec, the message signature can be found in the .well-known directory (here for OpenAI). To verify the ChatGPT signature we need to do the following:
Verify Signature-Agent equals "https://chatgpt.com" (with the quotes).
Fetch key from the .well-known directory and verify Signature using the description in Signature-Input per RFC 9421.
For my agent session above, the signature headers were logged on the server:
We can see that the request I triggered was indeed from OpenAI, even though it had a different IP and a standard Chrome user agent.
I can now use this to craft some nuanced rules around how I want to allow access to my site. For example:
Allow all search engine indexers to visit the entire site, but block unverified crawlers.
Block all other bots, except verified bots from OpenAI and Google.
Block all requests from hosting IPs on the website, except verified requests from OpenAI’s agent.
Allow all requests from hosting IPs to our API. APIs are designed for automated requests which may come from a script running on a server.
You can of course implement this yourself, but that’s where Arcjet comes in! Our bot detection features allow you to manage all this in just a few lines of code.
Announcing Arcjet’s local AI security model, an opt-in AI security layer that runs expert security analysis for every request entirely in your environment, alongside our Series A funding.
Google AI Overviews are causing fewer clicks for some site owners. If this is a fundamental shift in the web's traffic economy, how can site owners control where their content appears?
Detect, block, and redact PII locally without sending it to the cloud using Arcjet's sensitive information detection, plus the new integration with LangChain.